


has been a shift in how basis fashions function.
After establishing that pretraining a big deep studying mannequin on an enormous corpus of temporal knowledge grants generalizable properties, pretrained TS fashions now purpose to be much more versatile.
For time sequence, this implies supporting exogenous variables and permitting variable context and prediction lengths.
This text discusses Timer-XL[1], an upgraded time sequence mannequin based mostly on Timer[2]. Timer-XL is constructed for generalization, with a give attention to long-context forecasting.
Let’s get began!
What’s Timer-XL
Timer-XL is a decoder-only Transformer basis mannequin for forecasting. The mannequin emphasizes generalizability and long-context predictions — providing unified, long-range forecasting.
Key options of Timer-XL:
- Various enter/output lengths: In contrast to fashions akin to Tiny-Time-Mixers which have numerous variations for various enter or output lengths, Timer-XL makes use of a single mannequin for all circumstances, with out making assumptions about context or prediction size.
- Lengthy-context forecasting: Handles longer lookback home windows successfully.
- Wealthy options: Forecasts non-stationary univariate sequence, advanced multivariate dynamics, and covariate-informed contexts with exogenous variables — all in a unified setup.
- Versatile: Could be skilled from scratch or pretrained on giant datasets. Additional finetuning is elective for improved efficiency.
Timer-XL enhances forecasting accuracy by introducing TimeAttention — a chic consideration mechanism that we’ll talk about intimately under.
The staff behind Timer-XL (THUML lab at Tsinghua College[3]) has deep experience in time-series modeling. They’ve launched milestone fashions like iTransfomer, TimesNet, and Timer — Timer-XL’s predecessor.
Encoder vs Decoder vs Encoder-Decoder fashions
Earlier than discussing Timer-XL, we’ll discover the associated work and recap the state of basis TS fashions — this can assist us perceive what led to Timer-XL’s breakthrough.
NLP Functions
Within the early days of the Transformer, there was debate over which structure was best. The unique Transformer was an Encoder-Decoder mannequin.
Later, the Transformer analysis break up into 2 branches: Encoder-only, like BERT (led by Google), and decoder-only, like GPT (led by OpenAI):
- Encoder-Decoder fashions use a bidirectional encoder to know enter and a causal decoder to generate output one token at a time. They excel at sequence-to-sequence duties akin to translation and summarization.
- Encoder-only fashions use bidirectional consideration (search for context in each methods) to know a sentence and predict masked phrases inside a sentence. They excel at NLU (pure language understanding) duties.
- Decoder-only fashions use causal consideration (the mannequin solely appears to be like again for context) and be taught to foretell the following phrase. They excel at NLG (pure language era) duties.
In NLP, decoder-only fashions dominate era duties. Encoder-only fashions are utilized in classification, regression, and NER (Named Entity Recognition).
Time-Collection Functions
By late 2024 and early 2025, quite a few basis fashions had been revealed, offering ample proof of what works greatest.
All these basis fashions have are available many flavours. Examples are:
Thus far, decoder and encoder-decoder fashions outperform encoders in forecasting. Timer-XL’s authors again this up with intensive experiments — their outcomes assist the identical conclusion.
There’s additionally a class of multi-purpose fashions — used for forecasting, classification, imputation, and many others. MOMENT and UNITS belong right here and are encoder-only fashions.
Timer, additionally multi-purpose, is a decoder-only mannequin. Its successor, Timer-XL, outperforms Timer in forecasting, however makes a speciality of that activity alone.
Due to this fact:
- For duties that require basic time-series understanding (e.g., imputation, anomaly detection), encoder fashions could also be extra appropriate.
- Nonetheless, for time-series forecasting, decoders presently maintain the lead.
That is why the authors shifted from Timer’s generalist design to Timer-XL’s specialization in forecasting. Each fashions are decoders, however the decoder structure advantages the forecasting activity!
Lengthy-Context Forecasting
The first benefit of Transformer fashions is their capacity to deal with a big context size.
Fashionable LLMs akin to Gemini assist as much as 1M tokens. They’re not flawless at this scale, however usually dependable as much as 100k tokens.
Time-series fashions are far behind — Transformer and DL forecasting fashions usually battle past 1K tokens. Current basis fashions akin to MOIRAI assist as much as 4K.
There are 2 points to look at right here:
- The utmost supported context size.
- How the mannequin handles the elevated context size, by way of efficiency.
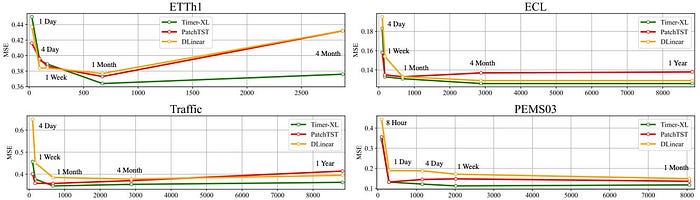
Determine 2 reveals that Timer-XL handles growing context higher than different fashions.
For each day datasets akin to Site visitors, we are able to use as much as a yr’s knowledge (~8760 datapoints). This makes Timer-XL splendid for high-frequency forecasting — a configuration the place basis fashions usually underperform, as mentioned earlier.
Since we beforehand mentioned Encoder-vs-Decoder fashions, let’s point out how this paper explored how every structure impacts the effectivity of Lengthy-Context Forecasting.
In Determine 3, they analyzed the place the mannequin focuses throughout prediction utilizing consideration maps:
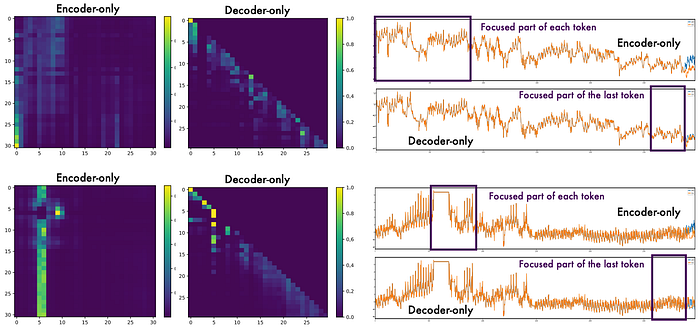
Let’s interpret the above plots:
Encoder: Displays broad and diffuse consideration throughout a lot of the sequence. Every token attends to many different tokens — this means much less focus. Often, they give attention to irrelevant components, fully lacking the newest datapoints.
Decoder: Sparse, triangular construction. Consideration is usually native and causal (as anticipated), however selective peaks counsel it sometimes “reaches again” additional when helpful.
Encoder fashions scatter their consideration throughout the sequence. Decoder fashions give attention to current tokens however adaptively zoom in on helpful earlier ones.
TimeAttention: The “Secret Sauce” of Timer-XL
The eye mechanism powers the Transformer (a breakthrough in NLP), however in time sequence, it’s a double-edged sword. We mentioned this extensively here.
In brief:
- Transformer Time Collection fashions are susceptible to overfitting.
- We can’t use uncooked consideration as in NLP as a result of self-attention is permutation-invariant (the order of tokens doesn’t matter, which it ought to when now we have temporal info).
Let’s first study how deep studying fashions handle time sequence, specializing in SOTA strategies from annually.
Preliminaries
In DL time sequence, a single knowledge level or a patch (a bunch of consecutive knowledge factors) is known as a token.
Think about a dataset of three time sequence, the place y is the goal variable and x, z are noticed covariates. For an enter dimension T, the sequences are formatted as:
- y1, y2, y3 … yT
- x1, x2, x3 … xT
- z1, z2, z3 … zT
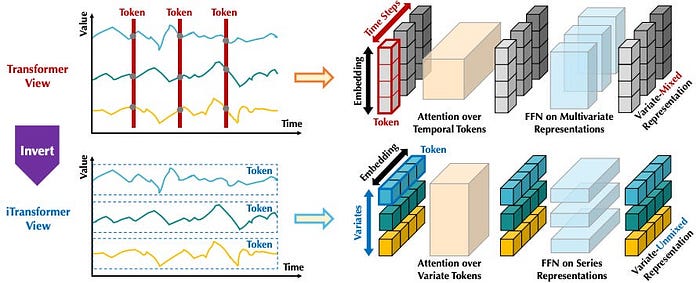
Early Transformer fashions like PatchTST utilized consideration throughout the time dimension, e.g., between
This method has just a few disadvantages — e.g., misses lagged info throughout the characteristic dimension.
Later fashions, akin to iTransformer, addressed this by making use of consideration throughout the characteristic/variate dimension, between
As you might need guessed, we are able to additional enhance efficiency by combining each approaches. For example, CARD (an encoder-only mannequin) employs a sequential 2-stage consideration mechanism for cross-time, cross-feature dependencies (Determine 5):
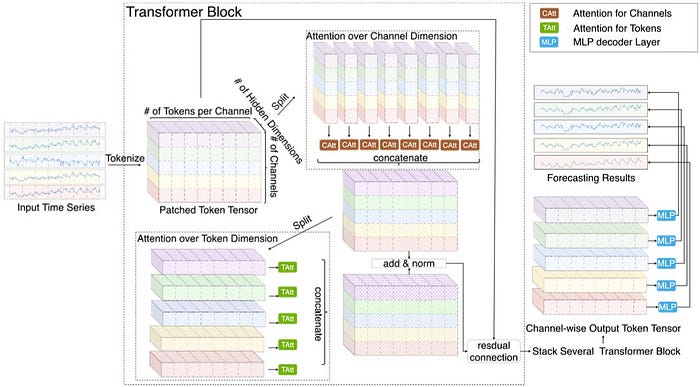
Nonetheless, this methodology is gradual — resulting from its sequential 2-stage design.
MOIRAI took issues to the following degree by introducing Any-Variate Consideration, a novel consideration mechanism tailored for pretrained fashions.
Any-Variate captures temporal relationships amongst datapoints whereas preserving permutation invariance throughout covariates. We mentioned this mechanism intimately here.
Subsequent, we dive into Timer-XL’s TimeAttention.
Enter TimeAttention
MOIRAI is a masked encoder mannequin, so Any-Variate Consideration can’t be used as-is in decoder-only fashions like Timer-XL.
Decoder-only fashions use causal self-attention — attending solely to earlier tokens. In distinction, vanilla quadratic self-attention is bidirectional.
To deal with this, Timer-XL introduces a causal variant of MOIRAI’s consideration referred to as TimeAttention.
Particularly, TimeAttention introduces:
- Rotary positional embeddings (ROPE) to seize time dependencies
- Binary biases (ALIBI) to seize dependencies amongst variates.
- Causal self-attention.
The objective of TimeAttention is:
- No permutation invariance for temporal info — the ordering of datapoints/temporal tokens ought to matter.
- Permutation invariance between the variates/options — ordering of the variates shouldn’t matter (e.g., if now we have 2 covariates
X1andX2, it doesn’t matter which is first, simply the connection between them). This achieves permutation equivalence.
The eye rating between the (m,i)-th question and the (n,j)-th key, the place i,j symbolize the time indexes and (m,n) the variate indexes, is calculated as follows:
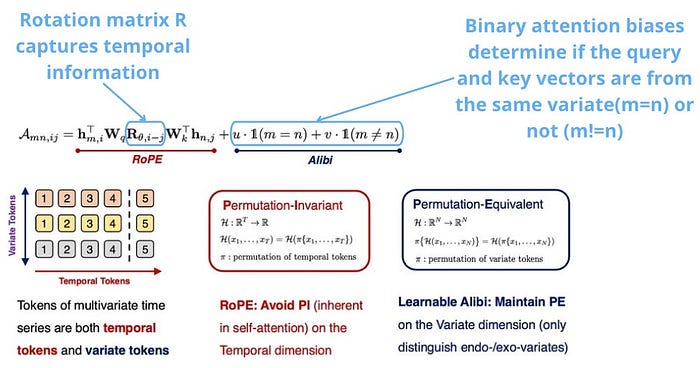
TimeAttention permits Timer-XL to deal with univariate, multivariate, and context-informed forecasting.
Given N variables for a dataset, the mannequin flattens the 2D enter [observations, N] into 1D indices and calculates the attention-score by respecting permutation invariance within the time dimension and permutation equivariance within the variate dimension.
Normal self-attention is pairwise, leading to quadratic value. A key distinction from MOIRAI is using causal consideration, the place every patch attends to earlier factors of its personal sign, or to different time alerts.
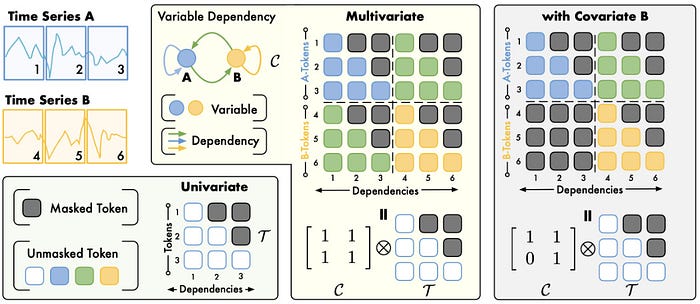
In Determine 7’s instance, say now we have 2 time sequence, A and B, every consisting of three tokens. The interactions are proven extra clearly in Determine 8:
- Time Collection A consists of tokens 1, 2, and three
- Time Collection A consists of tokens 4, 5, and 6
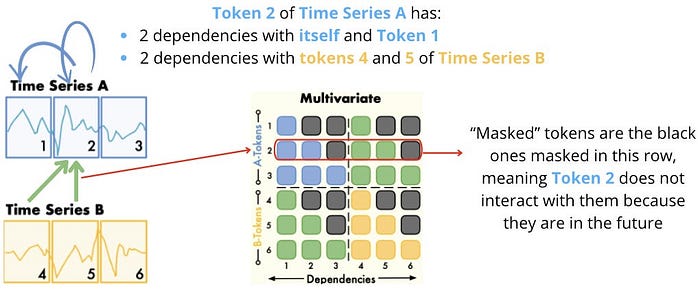
For Token 2 of Time Collection A, the next consideration scores are calculated:
- token2 ←→ token2 (to itself)
- token2 ←→ token1
- token2 ←→ token4
- token2 ←→ token5
The primary 2 consideration scores are inside time sequence A, whereas the final 2 are inside time sequence B. The TimeAttention formulation can distinguish completely different time sequence and protect permutation-equivalence.
Whereas TimeAttention could seem advanced and considerably arbitrary, ablation research carried out by the authors present it gives optimum efficiency on this setup.
Observe: After we point out tokens, we don’t imply particular person datapoints. Timer-XL makes use of patches as tokens — so consideration scores are computed between patches, not particular person datapoints.
Enter Timer-XL
The complete structure of Timer-XL is proven under:
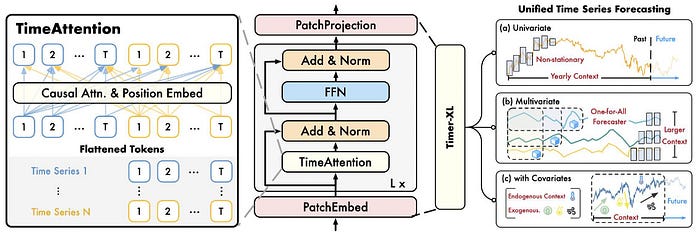
Timer-XL focuses on long-context and long-term forecasting utilizing TimeAttention. Furthermore, Timer-XL makes use of the most recent perks of superior LLMs like FlashAttention:
FlashAttention hurries up Transformer consideration and reduces reminiscence use by optimizing matrix operations and eliminating redundant steps.
Curiously, Timer-XL does not profit from Reversible Occasion Normalization (RevIN) — a way usually used to deal with distribution shifts in time-series knowledge. The authors attribute this to the window-centric construction of Timer-XL, which operates throughout completely different variates (doubtless as a result of flattening course of).
Let’s now verify some fascinating benchmarks! Final yr, I revealed a tutorial for Timer-based functions in my e-newsletter:
Timer-XL Revisited: A Hands-On Guide to Zero-Shot Forecasting
Multivariate Forecasting Benchmark
Timer-XL is primarily a zero-shot basis mannequin, but it surely will also be skilled from scratch on particular datasets.
In Desk 1, Timer-XL is benchmarked towards fashionable DL fashions throughout well-known datasets. For every dataset, common MAE and MSE are reported utilizing a rolling-forecast analysis throughout the check set.
Rolling Forecasting: On this method, every mannequin is skilled with 672 enter steps to provide N = (96, 192, 336, or 720) output steps. The earlier window slice of actual observations is then recursively fed again as enter till the goal forecast size N is reached. Desk 1 reveals the typical rating throughout all prediction lengths.
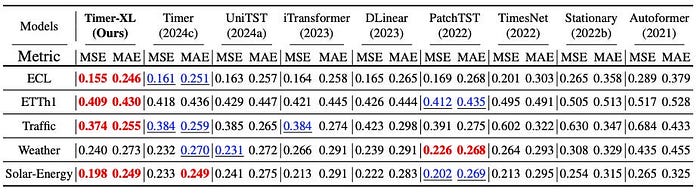
Key takeaways:
- Timer-XL achieves one of the best common scores.
- Earlier SOTA fashions like PatchTST and iTransformer ranked among the many prime 2 in just a few circumstances.
- Timer-XL and Timer — the one decoder-only fashions — carry out one of the best.
The benchmark is additional prolonged to incorporate time-series fashions from different domains. Beneath are outcomes from the GTWSF dataset (a wind velocity forecasting problem):
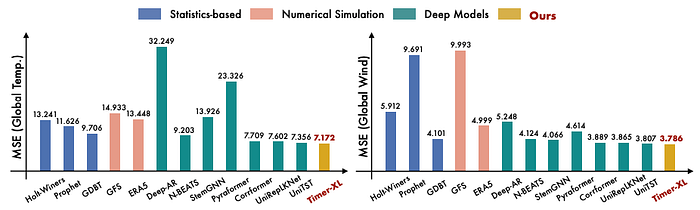
We observe:
- Timer-XL achieves the highest total rating.
- Most DL fashions carry out effectively, although some fail spectacularly!
- GDBT is just not a statistics-based methodology, in all probability refers to Boosted Timber — actually, it will be good if the favored GDBT fashions like LightGBM had been current right here.
- A Seasonal Naive baseline would’ve been a helpful inclusion as effectively.
Covariate-Knowledgeable Time Collection Forecasting
In multivariate forecasting, every time sequence is handled as a separate channel. The mannequin captures their inter-dependencies and collectively forecasts all time sequence.
In covariate-informed forecasting, we predict a goal sequence utilizing others as covariates. These could also be past-observed, future-known, or static. That’s the setup mentioned right here.
An instance of covariate-informed forecasting is proven in Determine 7 (proper). In that case we predict variable A based mostly on its dependency (inexperienced arrow) from B.
Desk 2 reveals outcomes on the EPF dataset (electrical energy worth forecasting activity, Lago et al., 2021). The authors embrace each the present Timer-XL and an encoder Timer-XL variant (the one with the non-causal tag).
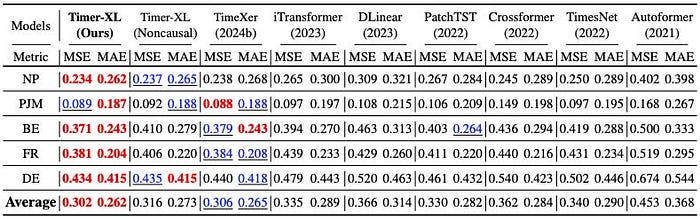
Observe that:
- Timer-XL achieves one of the best outcomes.
- The decoder model (Timer-XL) outperforms the encoder-based Timer-XL.
- TimerXer is an encoder-based Transformer that makes use of cross-attention to mannequin dependencies with exogenous variables, every handled as a separate token. This was a earlier SOTA DL mannequin — now outperformed by Timer-XL.
Zero-Shot Forecasting Benchmark
Lastly, the authors additionally consider Timer-XL as a basis mannequin, evaluating it with different prime time sequence fashions.
They carry out univariate pretraining on the LOTSA dataset (used to pretrain MOIRAI) and UTSD. The latter was curated by the THUML analysis group and used to pretrain Timer. It incorporates 1B datapoints.
The identical metrics and configurations as earlier than are used (e.g., scores averaged throughout prediction_lengths ={96, 192, 336, 720}). This time, not one of the fashions had been skilled on the under datasets (zero-shot forecasting).
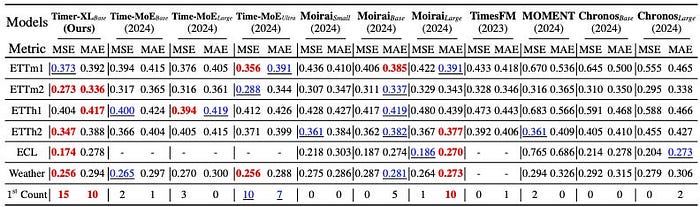
We discover the next:
- Timer-XL-base (the zero-shot model) scores probably the most wins.
- Time-MOE-ultra ranks 2nd, adopted by the MOIRAI fashions.
- Curiously, MOIRAI-Base takes some wins from MOIRAI-Massive — a sample seen in different benchmarks. Regardless of having fewer parameters, MOIRAI-Base usually matches or outperforms MOIRAI-Massive.
- Sadly, the SOTA variations of current pretrained fashions aren’t included. For instance, newer variations like TimesFM-2.0, Chronos-Bolt, MOIRAI-MOE, and different fashionable fashions, akin to Tiny-Time-Mixers (TTM) and TabPFN-TS, are lacking.
The authors have included the whole benchmark of basis fashions in Desk 13 of the paper. Be happy to learn the paper for extra particulars. In these outcomes, I seen that Timer-XL performs barely higher with longer prediction lengths in comparison with the opposite fashions.
Interpretability
Few time-series fashions discover interpretability, particularly the DL fashions. Timer-XL authors exhibit the advantages of consideration by exhibiting the way it captures interdependencies amongst time sequence variables.
Determine 11 reveals the typical consideration rating throughout all consideration matrices. The matrix is 10×10, which corresponds to the eye rating pairs amongst 10 variables. The two tiles within the determine present the connection between consideration and correlation. The pair of variables <6,7> has a better consideration rating than <6,2> — which appropriately interprets to the pair <6,7> having a better correlation.
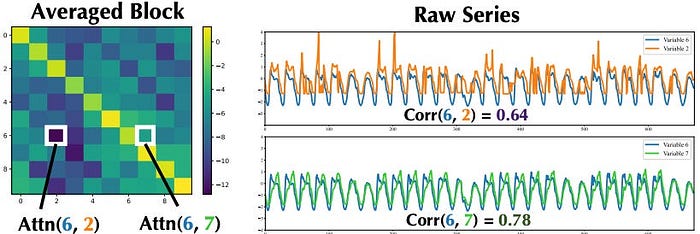
Therefore, we conclude:
The Transformer’s consideration mechanism learns to interpret the internal dependencies between the completely different variables.
This isn’t a brand new sample — now we have seen many Transformer forecasting fashions utilizing this trick. On this case, it means Timer-XL’s consideration mechanism works as anticipated and appropriately captures the variate dependencies.
Univariate Forecasting Tutorial
On the time of writing this text, the authors have launched the univariate pretrained model of Timer-XL.
Thus, I used this model for now to judge Timer-XL on the ETTh2 dataset and the most recent month of the SP&500 index.
The outcomes are fairly promising. Determine 12 reveals Timer-XL’s predictions on the ETTh2 dataset:
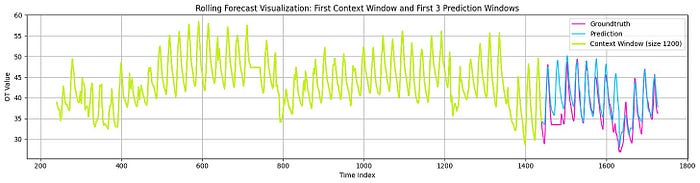
I don’t wish to make this text very lengthy, so we’ll undergo the tutorials on Half 2. You can too discover them within the AI Projects Folder (Challenge 18 and Challenge 19). Keep tuned!
Thanks for studying!
References
[1] Liu et al. Timer-XL: Long-context Transformers For Unified Time Series Forecasting(March 2025)
[2] Liu et al. Timer: Generative Pre-trained Transformers Are Large Time Series Models (October 2024)
[3] THUML @ Tsinghua University
[4] Liu et al. Timer-XL ICRL2025 Presentation Slides