


: Overparameterization, Generalizability, and SAM
The dramatic success of recent deep studying — particularly within the domains of Laptop Imaginative and prescient and Pure Language Processing — is constructed on “overparameterized” fashions: fashions with greater than sufficient parameters to memorize the coaching information completely. Functionally, a mannequin will be identified as overparameterized when it might simply obtain a near-perfect coaching accuracy (near 100%) with near-zero coaching loss for a given activity.
Nevertheless, the usefulness of such a mannequin is determined by whether or not it performs nicely on the held-out check information drawn from the identical distribution because the coaching set, however unseen throughout coaching. This property is known as “generalizability” — the flexibility of a mannequin to take care of efficiency on new examples — and it’s important for any deep studying mannequin to be virtually helpful.
Classical Machine Studying concept tells us that overparameterized fashions ought to catastrophically overfit and subsequently generalize poorly. Nevertheless, some of the stunning discoveries of the previous decade is that fashions on this class typically generalize remarkably nicely.
This extremely counterintuitive phenomenon has been investigated in a sequence of papers, beginning with the seminal works of Belkin et al. (2018) and Nakkiran et al. (2019), which demonstrated that there exists a “double descent” curve for generalizability: as mannequin measurement will increase, generalization first worsens (as classical concept predicts), then improves once more past a important threshold — offered the mannequin is skilled with the suitable optimization strategies.
Determine 1 exhibits a cartoon of a double descent curve. The y-axis plots check error — a measure of generalizability, the place decrease error signifies higher generalization — whereas the x-axis exhibits the variety of mannequin parameters. As mannequin measurement will increase, coaching error (dashed blue line) quickly approaches zero, as anticipated.
The check error (stable blue line) displays a extra fascinating habits: it initially decreases with mannequin measurement — the primary descent, highlighted by the left pink circle — after which rises to a peak on the interpolation threshold marked by the vertical dashed line, the place the mannequin has the worst generalization. Past this threshold, nevertheless, within the overparameterized regime, the check error decreases once more — the second descent, highlighted by the best pink circle — and continues to say no as extra parameters are added. That is the regime of curiosity for contemporary deep studying fashions.
In Machine Studying, one finds the parameters of a mannequin by minimizing a loss perform on the coaching dataset. However does merely minimizing our favourite loss perform — like cross-entropy — on the coaching dataset assure passable generalization properties for the category of overparametrized fashions? The reply is — typically talking — no! Whether or not one is fascinated about fine-tuning a pre-trained mannequin or coaching a mannequin from scratch, it is very important optimize your coaching algorithm to make sure that you’ve got a sufficiently generalizable mannequin. That is what makes the selection of the optimizer a vital design alternative.
Sharpness-Conscious-Minimization (SAM) — launched in a paper by Foret et al. (2019) — is an optimizer designed to enhance generalizability of an overparameterized mannequin. On this article, I current a pedagogical overview of SAM that features:
- An intuitive understanding of how SAM works and why it improves generalization.
- A deep dive into the algorithm, explaining the important thing mathematical steps concerned.
- A PyTorch implementation of the optimizer class in a coaching loop, together with an vital caveat for fashions with BatchNorm layers.
- A fast demonstration of the effectiveness of the optimizer in bettering generalization on a picture classification activity with a ResNet-18 mannequin.
The whole code used on this article will be present in this Github repo — be at liberty to mess around with it!
The Notion of Sharpness
To start with, allow us to attempt to get an intuitive sense of why merely minimizing the loss perform might not be sufficient for optimum generalization.
A helpful image to take into consideration is that of the loss panorama. For a big overparametrized mannequin, the loss panorama has a number of native and world minima. The native geometries round such minima can range considerably alongside the panorama. For instance, two minima might have practically similar loss values, but differ dramatically of their native geometry: one could also be sharp (slim valley) whereas the opposite is flat (broad valley).
One formal measure for evaluating these native geometries is “sharpness”. At any given level w within the loss panorama with loss perform L(w), sharpness S(w) is outlined as:

Let me unpack the definition. Think about you’re at a degree w within the loss panorama and also you perturb the parameters such that the brand new parameter all the time lies inside a ball of radius ρ with heart w. Sharpness is then outlined because the maximal change within the loss perform inside this household of perturbations. Within the literature, it’s also known as the worst-direction sharpness for apparent causes.
One can readily see that for a pointy minimal — a steep, slim valley — the worth of the loss perform will change dramatically with small perturbations in sure instructions and result in a excessive worth for sharpness. For a flat minimal then again — a large valley — the worth of loss perform will change comparatively slowly with small perturbations and result in a decrease worth for sharpness. Due to this fact, sharpness provides a measure of flatness for a given minimal within the loss panorama.
There exists a deep connection between the native geometry of a minimal — particularly the sharpness measure— and the generalization property of the resultant mannequin. Over the past decade, a big quantity of theoretical and empirical analysis has gone into clarifying this connection. As an illustration — because the paper by Keskar et al. (2016) factors out — world minima with related values of the loss perform can have considerably completely different generalization properties relying on their sharpness measures.
The fundamental lesson that appears to be emerge from these research is: flatter (much less sharp) minima are positively correlated with higher generalization of fashions. Specifically, the mannequin ought to keep away from getting caught in a pointy minima throughout coaching if it has to generalize nicely. Due to this fact, for coaching a mannequin with good generalization, one must be certain that the optimization process not solely minimizes the loss perform but additionally seeks to maximise the flatness (or equivalently reduce the sharpness) of the minima.
That is exactly the issue that the SAM optimizer is designed to resolve, and that is what we flip to within the subsequent part.
A fast apart: observe that the above image provides a conceptual rationalization of why an overparameterized mannequin can probably keep away from the issue of overfitting. It’s as a result of a big mannequin has a wealthy loss panorama which supplies a multiplicity of flat world minima with wonderful generalization properties.
The Sharpness-Conscious Minimization (SAM) Algorithm
Allow us to recall the usual optimization of a mannequin. It entails discovering mannequin parameters that reduce a given loss perform computed over a mini-batch B. At each time-step, one computes the gradient of the loss with respect to the parameters, and updates the parameters in accordance with the rule:

In contrast to SGD or Adam, SAM doesn’t reduce L immediately. As a substitute, at a given level within the loss panorama, it first scans its neighborhood of a given measurement ρ and finds the perturbation that maximizes the loss perform. Within the second step, it minimizes this most loss perform. This permits the optimizer to seek out parameters that lie in neighborhoods with uniformly low loss worth, which leads to smaller sharpness values and flatter minima.
Let’s focus on the process in a little bit extra element. The loss perform for the SAM optimizer is:
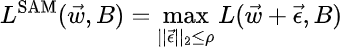
the place ρ denotes the higher certain on the dimensions of the perturbations. The perturbation that maximizes the perform L (typically known as adversarial perturbation because it maximizes the traditional loss) will be discovered by noting that:
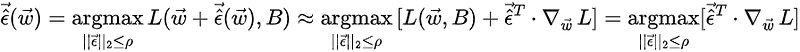
the place the second equality is an approximation obtained by Taylor-expanding the perturbed perform in step one, and the final equality follows from the ϵ-independence of the primary time period in sq. brackets within the earlier step. This final equality will be solved for the adversarial perturbation as follows:

Plugging this again within the equation for the SAM loss, one can compute the gradients of the SAM loss to the main order in derivatives of ϵ:

That is essentially the most essential equation for the optimization process. To the main order in derivatives of ϵ, the gradients of the SAM loss perform will be approximated by the gradients of the traditional loss perform evaluated on the adversarially perturbed level. Utilizing the above components for the gradients, one can now execute the usual optimizer step:

This completes one full SAM iteration. Subsequent, allow us to translate the algorithm from English to PyTorch.
PyTorch Implementation in a Coaching Loop
An illustrative instance of a coaching loop with a SAM optimizer is given within the code block sam_training_loop.py. For concreteness, now we have chosen a generic picture classification drawback, however the identical construction broadly holds for a variety of Laptop Imaginative and prescient and NLP duties. The SAM optimizer class is proven within the code block sam_optimizer_class.py.
Be aware that defining a SAM optimizer requires specifying two items of information:
- A base optimizer (like SGD or Adam), since SAM entails a regular optimizer step ultimately.
- A hyperparameter ρ, which places an higher certain on the dimensions of the admissible perturbations.
A single iteration of the optimizer entails two ahead passes and two backward passes. Let’s hint out the important thing steps of the code in sam_training_loop.py:
- Line 5 computes the loss perform L(w, B) for the present mini-batch B — the primary ahead cross.
- Line 6 computes the gradients of the loss perform L(w, B) — the primary backward cross.
- Line 7 calls the perform sam_optimizer.first_step from the SAM optimizer class (see beneath) that computes the adversarial perturbation utilizing the components mentioned above, and perturbs the weights of the mannequin as mentioned earlier than.
- Line 10 computes the loss perform for the perturbed mannequin — the second ahead cross.
- Line 11 computes the gradients of the loss perform for the perturbed mannequin— the second backward cross.
- Line 12 calls the perform sam_optimizer.second_step from the optimizer class (see beneath) that restores the weights to w_t after which makes use of the bottom optimizer to replace the weights w_t utilizing the gradients computed on the perturbed level.
A Caveat: SAM with BatchNorm
There is a vital level that one wants to bear in mind whereas deploying SAM in a coaching loop if the mannequin has any module that features batch-normalization layers. Throughout coaching, BatchNorm implements the normalization utilizing the present batch statistics and updates the operating statistics at each ahead cross. For analysis, it makes use of the operating statistics.
Now, as we noticed above, SAM entails two ahead passes per iteration. For the primary cross, BatchNorm works in the usual trend. In the course of the second cross, nevertheless, we’re utilizing perturbed weights to compute loss, and the naive coaching perform within the code block sam_training_loop.py will enable the BatchNorm layers to replace the operating statistics throughout the second cross as nicely. That is undesirable as a result of the operating statistics ought to solely replicate the habits of the authentic mannequin, not the perturbed mannequin which is just an intermediate step for computing gradients. Due to this fact, one has to explicitly disable the operating statistics replace throughout the second cross and allow it earlier than the following iteration.
For this function, we’ll use two specific features disable_bn_stats and enable_bn_stats within the coaching loop — easy examples of such features are proven in code block running_stat.py — they toggle the track_running_stats parameter (line 4 and line 9) of BatchNorm perform in PyTorch. The modified coaching loop is given within the code block mod_train.py.
Demo: Picture classification with ResNet-18
Lastly, let’s show how the SAM optimization improves the generalization of a mannequin in a concrete instance. We are going to contemplate a picture classification drawback utilizing the Fashion-MNIST dataset (MIT License): it consists of 60,000 coaching photos and 10,000 testing photos throughout 10 distinct, mutually unique courses, the place every picture is grayscale with 28*28 pixels.
Because the classifier mannequin, we’ll select a PreAct ResNet-18 with none pre-training. Whereas a dialogue on the exact ResNet-18 structure shouldn’t be very related for our function, allow us to recall that the mannequin consists of a sequence of constructing blocks, every of which is made up of convolutional layers, BatchNorm layers, ReLU activation with skipped connections. The PreAct (pre-activation) signifies that the activation perform (ReLU) comes earlier than the convolutional layer in every block. For the standard ResNet-18, it’s the different manner spherical. I’d refer the reader to the paper — He et al. (2015) — for extra particulars on the structure.
What’s vital to notice, nevertheless, is that this mannequin has about 11.2 million parameters, and subsequently from the angle of classical Machine Studying, it’s an overparameterized mannequin with the parameter-to-sample ratio being about 186:1. Additionally, because the mannequin consists of BatchNorm layers, now we have to watch out about disabling the operating statistics for the second cross, whereas utilizing SAM.
We at the moment are prepared to hold out the next experiment. We practice the mannequin on the Style-MNIST dataset with the usual SGD optimizer first after which with the SAM optimizer utilizing the identical SGD as the bottom optimizer. We are going to contemplate a easy setup with a hard and fast studying price lr=0.05 and with the momentum and the weight-decay each set to zero. The hyperparameter ρ in SAM is ready to 0.05. All runs are carried out on a single A100 GPU.
Since every SAM weight replace requires two backpropagation steps — one to compute the perturbations and one other to compute the ultimate gradients — for a good comparability every non-SAM coaching run should execute twice as many epochs as every SAM coaching run. We are going to subsequently have to check a metric from one epoch of SAM coaching run to a metric from two epochs of non-SAM coaching run. We are going to name this a “standardized epoch” and a metric recorded at standardized epochs shall be labelled as metric_st. We are going to prohibit the experiment to 150 standardized epochs, which implies the SAM coaching runs for 150 epochs and the non-SAM coaching runs for 300 epochs. We are going to practice the SAM-optimized mannequin for an extra 50 epochs to get an thought of how the mannequin behaves on longer coaching.
In attempting to test which optimizer provides higher generalization, we’ll evaluate the next two metrics after every standardized epoch of coaching:
- Take a look at accuracy: Efficiency of the mannequin on the check dataset.
- Generalizability hole: Distinction between the coaching accuracy and check accuracy.
The check accuracy is an absolute measure of how nicely the mannequin generalizes after a sure variety of coaching epochs. The generalizability hole, then again, is a diagnostic that tells you the way a lot a mannequin is overfitting at a given stage of coaching.
Allow us to start by evaluating the training_loss_st and training_accuracy_st graphs, as proven in Determine 3. The mannequin with SGD reaches near-zero loss and near 99% coaching accuracy inside 150 epochs, as anticipated of an overparametrized mannequin. It’s evident that SAM trains slowly in comparison with SGD and takes extra standardized epochs to succeed in a near-perfect coaching accuracy. That is evident from the truth that the coaching loss in addition to the coaching accuracy continues to enhance as one trains the SAM-optimized mannequin for extra epochs past the stipulated 150.

Take a look at accuracy. The graphs in Determine 4 compares the check accuracies for the 2 instances after every standardized epoch.

The SGD-optimized mannequin reaches 92% check accuracy round epoch 50 and plateaus round that worth for the following 100 epochs. The SAM-optimized mannequin generalizes poorly within the preliminary part of the coaching — till round 80 epochs — as evident from the decrease check accuracies on this part in comparison with the SGD graph. Nevertheless, round epoch 80, it catches up with the SGD graph and ultimately surpasses it by a skinny margin.
For this particular run, on the finish of 150 epochs, the check accuracy for SAM stands at test_SAM = 92.5%, whereas that for SGD is test_SGD = 92.0%. Be aware that that is even though the SAM-trained mannequin has a a lot decrease coaching accuracy and coaching loss at this stage. If one trains the SAM-model for one more 50 epochs, the check accuracy improves barely to 92.7%.
Generalization Hole. The evolution of the generalization hole after every standardized epoch in course of the coaching course of is proven in Determine 5.

The hole for the SGD mannequin grows steadily with coaching and after 150 epochs reaches gap_SGD=6.8%, whereas for SAM it grows far more slowly and reaches gap_SAM= 2.3%. On additional coaching for one more 50 epochs, the hole for SAM climbs to round 3%, however it’s nonetheless a lot decrease in comparison with the SGD worth.
Whereas the distinction in check accuracies is small between the 2 optimizers for the Style-MNIST dataset, there’s a non-trivial distinction within the generalization gaps, which demonstrates that optimizing with SAM results in higher generalization.
Concluding Remarks
On this article, I offered a pedagogical overview of SAM as an optimizer that considerably improves the generalization of overparameterized deep studying fashions. We mentioned the motivation and instinct behind SAM, walked by a step-by-step breakdown of the algorithm, and studied a easy instance demonstrating its effectiveness in comparison with a regular SGD optimizer.
There are a number of fascinating features of SAM that I didn’t have an opportunity to cowl right here. Let me briefly point out two of them. First, as a sensible instrument, SAM is especially helpful for fine-tuning pre-trained fashions on small datasets — one thing explored intimately by Foret et al.(2019) for CNN-type architectures and in lots of subsequent works for extra normal architectures. Second, since we opened our dialogue with the connection between flat minima within the loss panorama and generalization, it’s pure to ask whether or not a SAM-trained mannequin — which demonstrably improves generalizability — does certainly converge to a flatter minimal. This can be a non-trivial query, requiring a cautious evaluation of the Hessian spectrum of the skilled mannequin and a comparability with its SGD-trained counterpart. However that’s a narrative for one more day!
Thanks for studying! When you have loved the article, and would have an interest to learn extra pedagogical articles on deep studying, do comply with me on Medium and LinkedIn. Except in any other case acknowledged, all photos and graphs used on this article have been generated by the writer.