


I in my earlier article, “From Code to Insights: Software Engineering Best Practices for Data Analysts”, that engineering abilities and greatest practices might be extremely helpful for analysts and different information professionals.
That is much more true now within the AI period, when we have now much more alternatives to construct our personal analytical instruments: from fancy information viewers that show charts or showcase totally different eventualities, to simulators that may predict outcomes primarily based on enter parameters. Personally, I exploit net purposes on a regular basis in my day-to-day work.
There was numerous hype round vibe coding, however plainly skilled engineers are already shifting past it and leaning extra towards spec-driven growth. Even Andrej Karpathy, who coined the time period “vibe coding” in February 2025, admitted only a yr later that this period is ending and that we’re getting into the age of agentic engineering — orchestrating brokers in opposition to detailed specs with human oversight.
At the moment (1 yr later), programming through LLM brokers is more and more changing into a default workflow for professionals, besides with extra oversight and scrutiny. The aim is to assert the leverage from using brokers however with none compromise on the standard of the software program. Many individuals have tried to give you a greater identify for this to distinguish it from vibe coding, personally my present favourite “agentic engineering”:
– “agentic” as a result of the brand new default is that you’re not writing the code instantly 99% of the time, you’re orchestrating brokers who do and appearing as oversight.
– “engineering” to emphasise that there’s an artwork & science and experience to it. It’s one thing you’ll be able to study and grow to be higher at, with its personal depth of a distinct variety.
On this article, I’d prefer to put spec-driven growth into observe on a greenfield mission, following the most effective practices from JetBrains’ course on DeepLearning.AI, “Spec-Driven Development with Coding Agents”.
The mission is a little more private, however nonetheless data-related. As I’m making ready for my half marathon in September, I’m making an attempt to stability working and power coaching. There are such a lot of instruments on the market, every centered on a distinct a part of the journey, that discovering one answer that actually works for me has been surprisingly tough. So, I made a decision to feed two birds with one scone: construct my very own net app whereas hopefully studying one thing new alongside the best way.
Prepared for motion? Me too. However earlier than we leap into implementation, let me first spend a couple of minutes on the speculation behind spec-driven growth.
Vibe coding vs Spec-driven growth
Many people have already skilled vibe coding: you write a brief immediate (for instance, “Please add a DAU chart to my net utility”), look forward to the agent to generate the change, run it domestically, and examine whether or not the consequence matches your expectations.
Normally, it doesn’t. So that you return to the identical chat, ask the agent to regulate the chart, and maintain iterating till the result’s ok.
This strategy works fairly effectively for easy tasks, nevertheless it doesn’t scale effectively, particularly when a number of builders are engaged on the identical codebase.
The principle drawbacks are the shortage of greatest practices and shared conventions. For instance, with no structured strategy, groups can simply find yourself with 5 alternative ways to run ML mannequin coaching inside the identical DBT pipeline.
One other widespread situation is that we often don’t persist the outcomes or reasoning from our conversations with AI brokers. In consequence, it turns into straightforward to lose observe of why sure selections had been made. For instance, an agent would possibly overlook why you cleaned up information in a selected approach, and the following replace might silently introduce a distinct consequence.
Context decay can also be an particularly widespread drawback. AI brokers are stateless, and when engaged on bigger tasks, we frequently have to start out new chats due to context window limitations, successfully beginning our communication from scratch.
Spec-driven growth (SDD) is far nearer to conventional engineering practices. As a substitute of leaping straight into implementation, we begin by doing the exhausting considering ourselves: making architectural selections, defining necessities, and documenting them in a structured markdown specification saved within the repository and up to date alongside the mission. This creates an necessary shift: we decouple the specification (what we’re constructing and why) from the implementation (the precise code).
SDD addresses lots of the core problems with vibe coding by preserving context throughout classes (and even throughout totally different AI brokers) whereas aligning each people and brokers across the mission’s most important non-negotiables.
SDD workflow
A typical spec-driven growth workflow often consists of the next levels.
Step one is defining the structure — an settlement on the important thing selections for the mission. It often contains a number of core paperwork:
- Mission explains the why: why are we constructing this mission, and what are its key targets and options?
- Tech Stack paperwork technical selections, in addition to deployment and replace processes.
- Roadmap outlines mission phases, deliberate options, and is repeatedly up to date because the mission evolves.
Specs might be created for each new and current tasks, which makes this strategy fairly versatile.
As soon as the project-level documentation is in place, we will transfer on to the function growth part, which generally contains:
- Understanding what we need to construct and writing an in depth specification.
- Implementing the adjustments.
- Validating that the implementation works as anticipated.
After efficiently implementing your first function, you would possibly instantly really feel the urge to maneuver on to the following one. However that is truly the precise second to pause and rethink.
That is the place replanning is available in. It’s a devoted part for revisiting the structure and reviewing earlier function selections and plans to verify they nonetheless align with the mission targets.
Now that we’ve lined the speculation, let’s put it into observe.
Constructing
Sufficient idea, it’s time to construct. To raised perceive how spec-driven growth works in observe, I made a decision to use it to an actual greenfield mission.
I began by creating a brand new repository for this mission (and, in fact, spending half an hour selecting the identify and emblem): repository. I additionally documented my preliminary product imaginative and prescient within the README.md file.
One of many good issues in regards to the SDD strategy is that it’s largely agnostic to the selection of LLM, agent, or IDE, so you’ll be able to work with no matter setup you like. For this mission, I’ll be utilizing Visible Studio Code with the Claude Code plugin, because it permits me to make use of Claude as an agent whereas additionally reviewing all code adjustments instantly within the editor.
Making a structure
As we mentioned, step one is to jot down the structure. In fact, we don’t have to do it manually, we will use LLMs to place it collectively primarily based on the preliminary product imaginative and prescient, in addition to further context gathered by follow-up questions.
We're constructing Trainlytics, a private health monitoring net app constructed
for individuals who need extra management, flexibility, and insights than normal
health apps present. Discover the complete necessities in README.md.
Let's create a "structure" in a specs listing that consists of
the next elements:
- mission.md - what and why we're constructing; the primary mission of the product
- tech-stack.md - core technical selections
- roadmap.md - mission phases damaged down in implementation order
IMPORTANT: It's essential to use your AskUserQuestion software to get my suggestions.The agent then asks a collection of clarifying questions that assist outline the mission structure and create an preliminary implementation plan.
In the long run, the agent created the three recordsdata we requested for.

At this level, you would possibly really feel the urge to right away ask the agent to start out constructing the mission, however that may be too quickly.
Earlier than shifting ahead, we first have to validate and refine the structure. It’s value spending time now aligning on the plan, as a result of this specification will later translate into 1000’s of strains of code. It’s significantly better to resolve ambiguities and errors early.
I often do that by studying the paperwork myself and iterating with the agent, asking clarifying questions and refining the plan step-by-step. A great observe is to make all adjustments by the agent slightly than patching paperwork your self to take care of consistency throughout the mission. For instance, I instructed the agent that we want authentication within the app, since my use case is to log exercises from each desktop and cell units. This led to updates in each the tech stack doc and the roadmap.

When you’re proud of the evaluation, it’s also possible to ask a second agent — with recent context — to critique the plan. There are lots of evidence that reflection improves output high quality.
When all checks are full, it’s time to commit the structure to the repository.
First function part
Now, it’s time to maneuver on the primary function part.
Based on our roadmap, we’ll begin with the MVP: Core Exercise Logging. On the finish of this part, a consumer ought to be capable to log in on each desktop and cell, document a run and a fitness center session, and examine each of their historical past with full particulars.
As mentioned, every function part follows a easy cycle: plan → implement → validate. So let’s begin by defining the specification and constructing the plan.
Discover the following part in specs/roadmap.md and create a brand new department,
ask me about any steps within the specs that aren't totally clear.
Then create a brand new listing within the format YYYY-MM-DD-feature-name underneath specs/
for this function, with the next recordsdata:
- plan.md - a structured checklist of numbered process teams
- necessities.md - scope, key selections, and context
- validation.md - how we outline success and ensure the implementation can
be merged
Use specs/mission.md and specs/tech-stack.md as steerage.Tip: it’s value beginning a brand new session with clear context in your LLM agent.
The agent put collectively specs fairly shortly.

At this level, it’s once more time to evaluation the specs and guarantee all the things is aligned with the unique imaginative and prescient. As you’ll be able to see, with agentic engineering, the function of the developer shifts towards steering, reviewing, and making architectural selections, slightly than instantly writing specs or code.
When you’re proud of the plan, it’s time to maneuver on to implementation. I desire to implement every group of duties individually slightly than one-shotting the complete function part, however this relies on the dimensions of the function. For this mission, I used the next immediate.
Take the following process group from 2026-05-04-phase-1-mvp/plan.md and implement it.
Use necessities.md and validation.md for steerage.
As soon as accomplished, replace the standing in each the plan and validation paperwork.When the code is prepared, it’s time for evaluation. This is without doubt one of the most necessary steps, so it’s value investing a while right here.
In data-related purposes, I often focus my evaluation on the core enterprise logic and examine that the numbers match my expectations.
I have to confess that I’ve near zero data of frontend applied sciences, so I not often evaluation frontend code intimately. As a substitute, I merely check the interface domestically and examine whether or not all the things works as anticipated. For this case, I made a decision to run the app and see the way it works.
After a number of iterations with the agent, we managed to run the app domestically, and it labored. We are able to already add totally different workout routines and exercise sorts, and log each cardio and power classes.
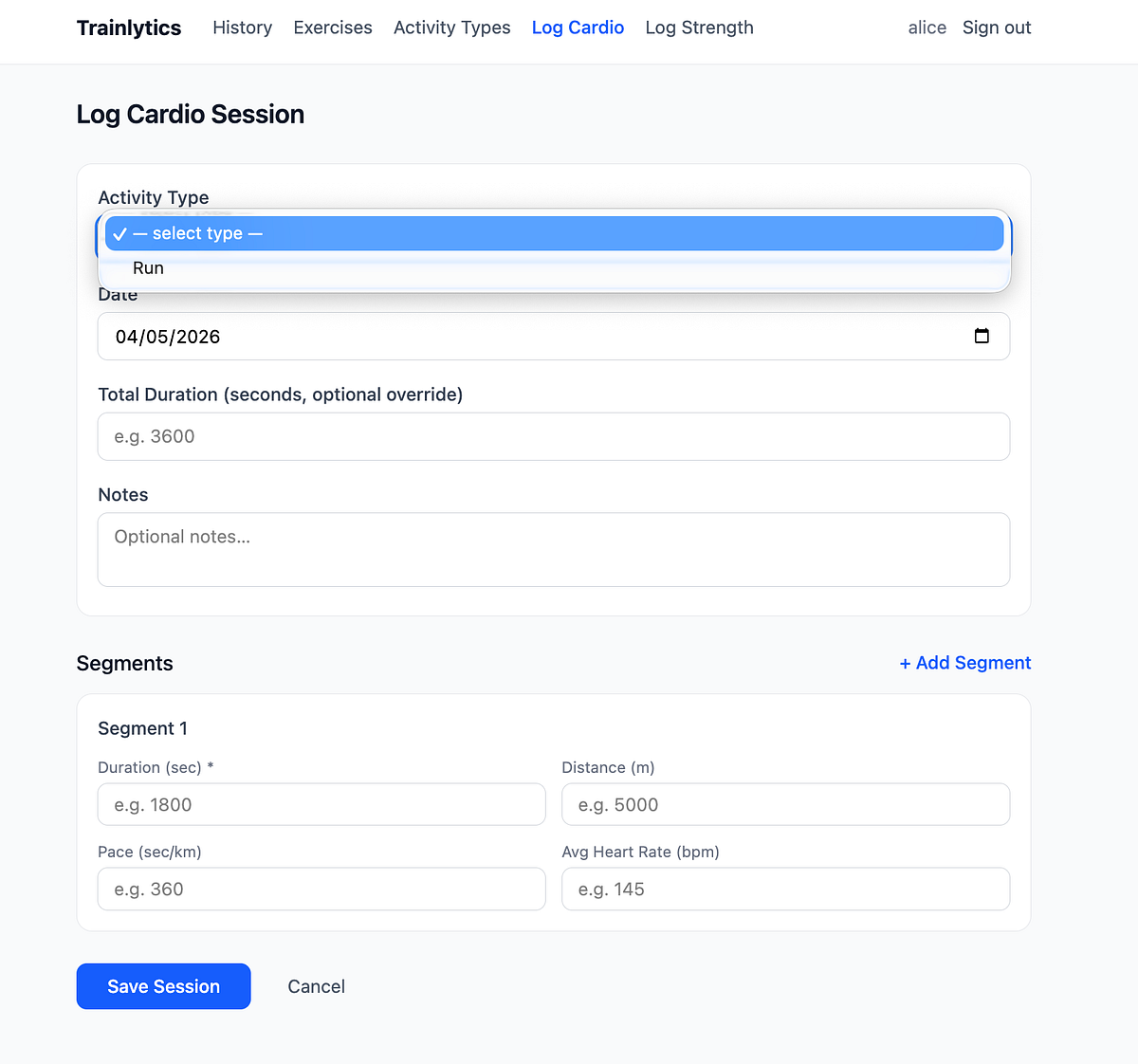
After the guide evaluation, it’s additionally helpful to make use of reflection and ask the brand new agent to confirm whether or not the implementation aligns with the plan, in addition to to undergo the factors outlined in validation.md.
In idea, spec-driven growth means that the function part ends with validation. In observe, it not often works that cleanly. You’ll possible discover that some elements of the implementation don’t work as anticipated. At that time, you could have two choices:
- Add a pair extra iterations to your
plan.mdand proceed refining the function (this works effectively for smaller adjustments), or - If the problems are extra substantial, deal with them as a part of the following function part and deal with them throughout replanning.
One necessary factor to be careful for: it may be tempting to easily clarify the problem to the LLM agent and ask for fixes, as an alternative of updating the specs and transforming the implementation. Attempt to withstand that shortcut. Maintaining the specification because the supply of reality is what makes the strategy sturdy.
As soon as all checks are full, we will create and merge the pull request.
At this level, we have already got a working utility and the outcomes are genuinely satisfying. Much more surprisingly, the entire course of took only a bit greater than two hours end-to-end (together with drafting this text whereas the agent was working).
Replanning
With such good progress, you would possibly really feel the urge to proceed constructing. I perceive that, however within the present AI period, the primary worth of a human lies in considering and structure. So that is truly the precise second to step again and mirror: can we nonetheless need to proceed in the identical route, and what ought to we modify in our product and course of?
Once I began utilizing the appliance myself, I realised it wasn’t but prepared to completely assist my use case. Meaning we have to reprioritise so I can begin utilizing it in my day-to-day life as quickly as attainable. So, I did it with the next immediate.
Let's revise our plan in roadmap.md.
I'd prioritise the following phases as follows:
1. Energy session templates
I can stay with out planning, however I want templates, as a result of I typically battle
to recollect all of the workout routines in a session.
The thought is:
- If a template already exists within the log, present all stats (workout routines, units,
reps, weight, and so on.). Permit modifying these values and committing adjustments
- If something is modified, ask whether or not the consumer desires to replace the template
2. UI enhancements
The present design will not be but glossy sufficient, so I would prioritise a spherical of UI
enhancements:
- Add the emblem and product motto to the web site
- Add a settings tab to handle exercise sorts and workout routines
- Create a single display to log each cardio and power classes
- Enhance the historical past display with richer exercise particulars
- Permit including titles to actions (power/cardio classes) and segments
- Help specifying time, not solely date
- Add extra shade to the interface (I like shades of blue)
- For cardio workout routines, modify models to: minutes, kilometers, and min/km tempo
3. Fundamental analytics
Add easy analytics to the historical past display displaying weekly stats at
the highest of the web page (e.g. whole minutes and energy break up between cardio
and power).Replanning can also be second to revisit our course of itself. For instance, I seen that we haven’t up to date roadmap.md persistently, and the specs are beginning to drift. It might even be helpful to introduce a changelog, so we have now a transparent historical past of how the product has developed over time.
Let’s ask agent to do it for us.
Please evaluation plan.md, replace roadmap.md to mirror accomplished work,
and create a CHANGELOG.md file with a concise abstract of the adjustments.Now that we’re aligned on route and have the precise setup in place, let’s maintain constructing.
The subsequent part
Now we will comply with the identical course of and iterate by phases. Since it is a repeatable cycle, it’s second to debate attainable automations.
Up to now, we’ve been writing all prompts manually, however these workflows may also be automated as “abilities” in Claude Code or different LLM coding brokers.
Additionally, there are already implementations of spec-driven growth that can be utilized out of the field. One of the vital well-liked is Spec Kit by GitHub.
You possibly can set up it like this.
uv software set up specify-cli --from git+https://github.com/github/spec-kit.git
specify model # to examine that it really worksSubsequent, you have to initialise the talents in Claude. This units up the .specify/ folder and installs slash instructions into .claude/instructions/
specify init . --integration claude
# there are 30 integrations with brokers so specify the one you are utilizingYou’ll understand it labored when see the speckit instructions within the Claude Code.
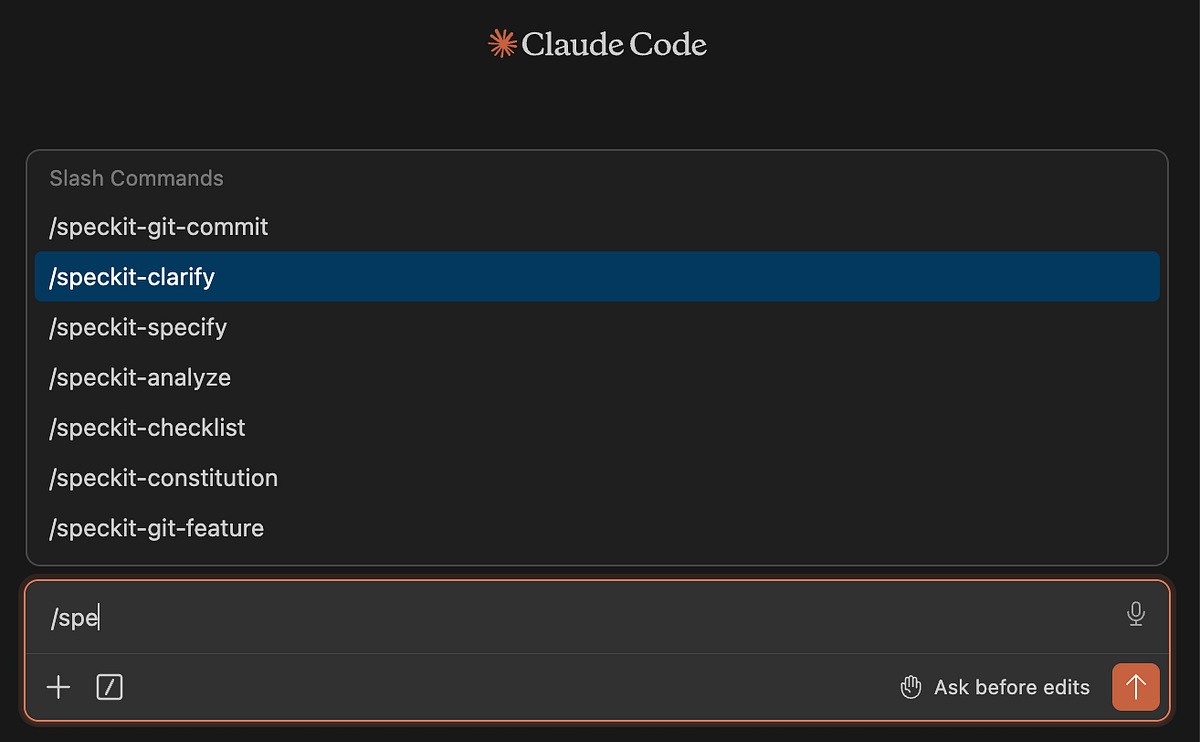
As soon as put in, you’ll be able to comply with an analogous workflow: begin by defining the structure, then iterate by function loops.
One distinction is that in Spec Package, the structure is extra centered on high-level issues like code high quality, testing requirements, UX consistency, and efficiency necessities.
To be sincere, I barely desire the strategy proposed by JetBrains, as a result of it retains extra context within the structure itself. However as at all times, there is no such thing as a silver bullet and Spec Package may go higher relying in your use case. It’s additionally handy that you’ve SDD workflow already applied for you.
Utilizing Spec Package, I ran by the 2 phases described above, and it labored effectively. After the primary function part, growth naturally turns into a steady enchancment cycle slightly than a linear course of. And with that, I believe it’s time to wrap up this story.
Abstract
In whole, it took me round 4.5 hours to construct a usable end-to-end product for monitoring and analysing my information. There may be nonetheless loads of room for enchancment, and I’ll proceed iterating on it. I can already see a number of potential UI enhancements, and I’d additionally prefer to finally combine AI to make the app extra clever.
Frankly talking, it has been an fascinating expertise working by such a structured growth movement. In my day-to-day work, I typically depend on one-off LLM chats to make adjustments, with out sustaining a full hint of selections and specs within the repository.
Nevertheless, there is no such thing as a one-size-fits-all strategy right here.
- If you happen to simply need to make a small enchancment or run some ad-hoc evaluation in yet one more Jupyter pocket book, writing full specs upfront might be overkill.
- However once you’re engaged on a bigger mission (particularly with different folks) spec-driven growth would positively be my default strategy.
It’s additionally fascinating to watch how the function of an engineer is shifting: from writing code on to focusing extra on architectural selections, evaluation, and system design.
And whereas it could sound a bit excessive as we speak, I do suppose we’re steadily shifting towards a world the place English turns into the first “programming language” interface. We’re already seeing early makes an attempt on this route, comparable to CodeSpeak, which discover extra natural-language-driven programming paradigms. I’ll strive CodeSpeak in my subsequent article, so keep tuned.
Reference
This text is impressed by the “Spec-Driven Development with Coding Agents” brief course from DeepLearning.AI.