


“What we discovered is that these AI brokers can do one thing that was beforehand very troublesome: ranging from free textual content (like an anonymized interview transcript) they’ll work their technique to the total identification of an individual,” Simon Lermen, a co-author of the paper, informed Ars. “It is a fairly new functionality; earlier approaches on re-identification usually required structured information, and two datasets with the same schema that might be linked collectively.”
In contrast to these older pseudonymity-stripping strategies, Lermen stated, AI brokers can browse the online and work together with it in lots of the similar methods people do. They will use simulated reasoning to match potential people. In a single experiment, the researchers checked out responses given in a questionnaire Anthropic took about how numerous individuals use AI of their day by day lives. Utilizing the knowledge taken from solutions, the researchers had been capable of positively determine 7 p.c of 125 contributors.
Finish-to-end deanonymization from a single interview transcript (with particulars altered to guard the topic’s identification). An LLM agent extracted structured identification alerts from a dialog, autonomously searched the online to determine a candidate particular person, and verified the candidate matched all extracted claims.
Finish-to-end deanonymization from a single interview transcript (with particulars altered to guard the topic’s identification). An LLM agent extracted structured identification alerts from a dialog, autonomously searched the online to determine a candidate particular person, and verified the candidate matched all extracted claims.
Whereas a 7 p.c recall is comparatively low, it demonstrates the rising functionality of AI to determine individuals primarily based on very normal data they gave. “The truth that AI can do that in any respect is a noteworthy end result,” Lermen stated. “And as AI programs get higher, they are going to probably get higher at discovering an increasing number of identities.”
In a second experiment, the researchers gathered feedback made in 2024 from the r/films subreddit and at the very least certainly one of 5 smaller communities: r/horror, r/MovieSuggestions, r/Letterboxd, r/TrueFilm, and r/MovieDetails. The outcomes confirmed that the extra films a candidate mentioned, the better it was to determine them. A median of three.1 p.c of customers sharing one film might be recognized with a 90 p.c precision, and 1.2 p.c of them at a 99 p.c precision. With 5 to 9 shared films, 90 p.c and 99 p.c precision rose to eight.4 p.c and a pair of.5 p.c of customers, respectively. Greater than 10 shared films bumped the proportion to 48.1 p.c and 17 p.c.
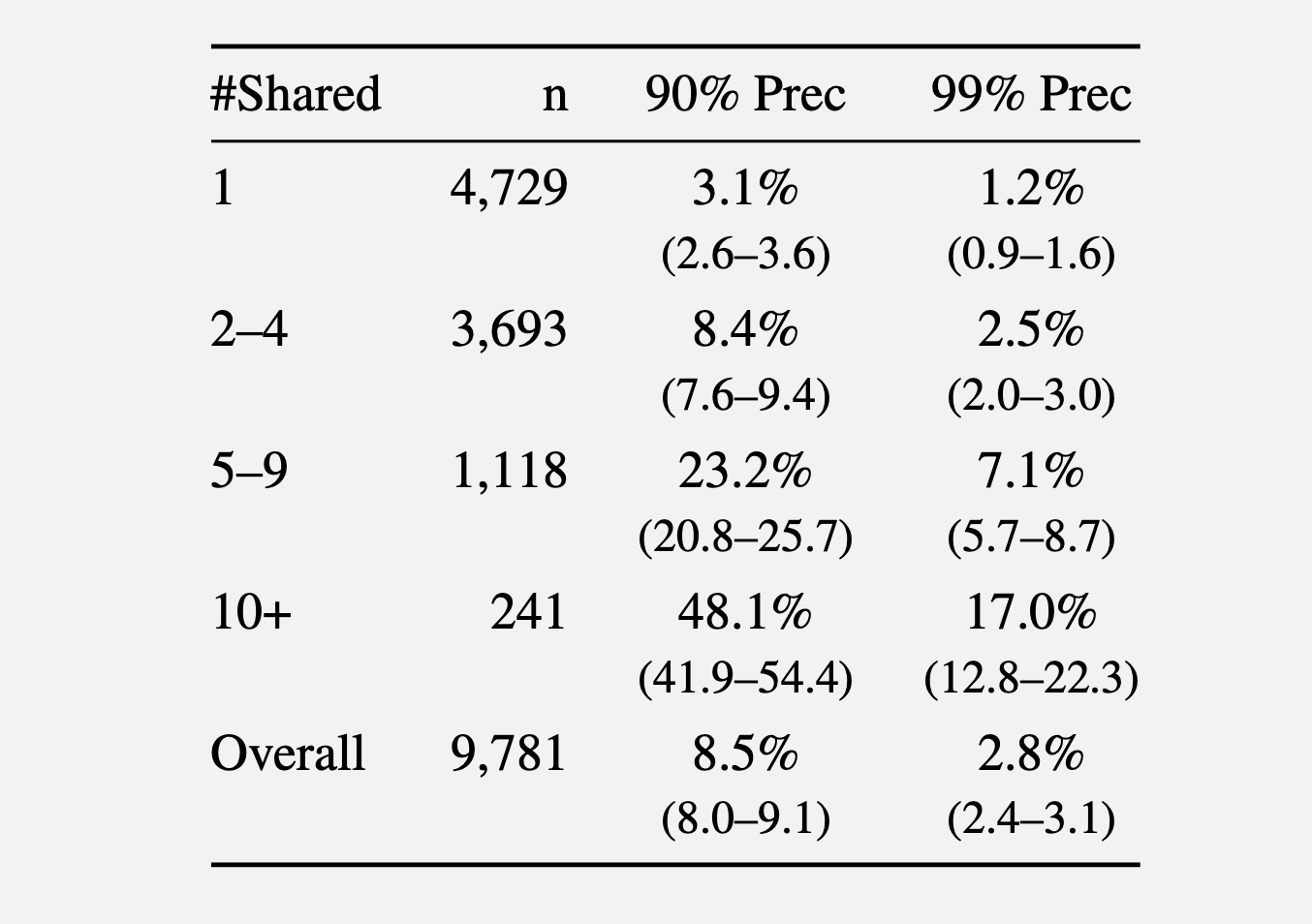
Recall at numerous precision thresholds.
Recall at numerous precision thresholds.
In a 3rd experiment, the researchers took a set of 5,000 Reddit customers. The researchers added 5,000 “distraction” identities of Reddit customers to the candidate pool. The researchers in contrast their technique to the older Netflix prize assault. They then added to the record of 10,000 candidate profiles 5,000 question distractors comprising customers who seem solely in a question set, with no true match within the candidate pool.