


a decade working in analytics, I firmly imagine that observability and analysis are important for any LLM utility operating in manufacturing. Monitoring and metrics aren’t simply nice-to-haves. They guarantee your product is functioning as anticipated and that every new replace is definitely shifting you in the proper course.
On this article, I need to share my expertise with the observability and analysis options of the NeMo Agent Toolkit (NAT). For those who haven’t learn my previous article on NAT, right here’s a fast refresher: NAT is Nvidia’s framework for constructing production-ready LLM functions. Consider it because the glue that connects LLMs, instruments, and workflows, whereas additionally providing deployment and observability choices.
Utilizing NAT, we constructed a Happiness Agent able to answering nuanced questions on the World Happiness report data and performing calculations primarily based on actual metrics. Our focus was on constructing agentic flows, integrating brokers from different frameworks as instruments (in our instance, a LangGraph-based calculator agent), and deploying the applying each as a REST API and a user-friendly interface.
On this article, I’ll dive into my favorite subjects: observability and evaluations. In any case, because the saying goes, you’ll be able to’t enhance what you don’t measure. So, with out additional ado, let’s bounce in.
Observability
Let’s begin with observability — the power to trace what’s occurring inside your utility, together with all intermediate steps, instruments used, timings, and token utilization. The NeMo Agent Toolkit integrates with quite a lot of observability instruments comparable to Phoenix, W&B Weave, and Catalyst. You may all the time verify the most recent listing of supported frameworks in the documentation.
For this text, we’ll attempt Phoenix. Phoenix is an open-source platform for tracing and evaluating LLMs. Earlier than we are able to begin utilizing it, we first want to put in the plugin.
uv pip set up arize-phoenix
uv pip set up "nvidia-nat[phoenix]"Subsequent, we are able to launch the Phoenix server.
phoenix serverAs soon as it’s operating, the tracing service will probably be obtainable at http://localhost:6006/v1/traces. At this level, you’ll see a default challenge since we haven’t despatched any information but.
Now, that the Phoenix server is operating, let’s see how we are able to begin utilizing it. Since NAT is predicated on YAML configuration, all we have to do is add a telemetry part to our config. You’ll find the config and full agent implementation on GitHub. If you wish to study extra in regards to the NAT framework, verify my previous article.
basic:
telemetry:
tracing:
phoenix:
_type: phoenix
endpoint: http://localhost:6006/v1/traces
challenge: happiness_reportWith this in place, we are able to run our agent.
export ANTHROPIC_API_KEY=
supply .venv_nat_uv/bin/activate
cd happiness_v3
uv pip set up -e .
cd ..
nat run
--config_file happiness_v3/src/happiness_v3/configs/config.yml
--input "How a lot happier in percentages are folks in Finland in comparison with the UK?" Let’s run a number of extra queries to see what sort of information Phoenix can monitor.
nat run
--config_file happiness_v3/src/happiness_v3/configs/config.yml
--input "Are folks total getting happier over time?"
nat run
--config_file happiness_v3/src/happiness_v3/configs/config.yml
--input "Is Switzerland on the primary place?"
nat run
--config_file happiness_v3/src/happiness_v3/configs/config.yml
--input "What's the major contibutor to the happiness in the UK?"
nat run
--config_file happiness_v3/src/happiness_v3/configs/config.yml
--input "Are folks in France happier than in Germany?"After operating these queries, you’ll discover a brand new challenge in Phoenix (happiness_report, as we outlined within the config) together with all of the LLM calls we simply made. This offers you a transparent view of what’s occurring underneath the hood.
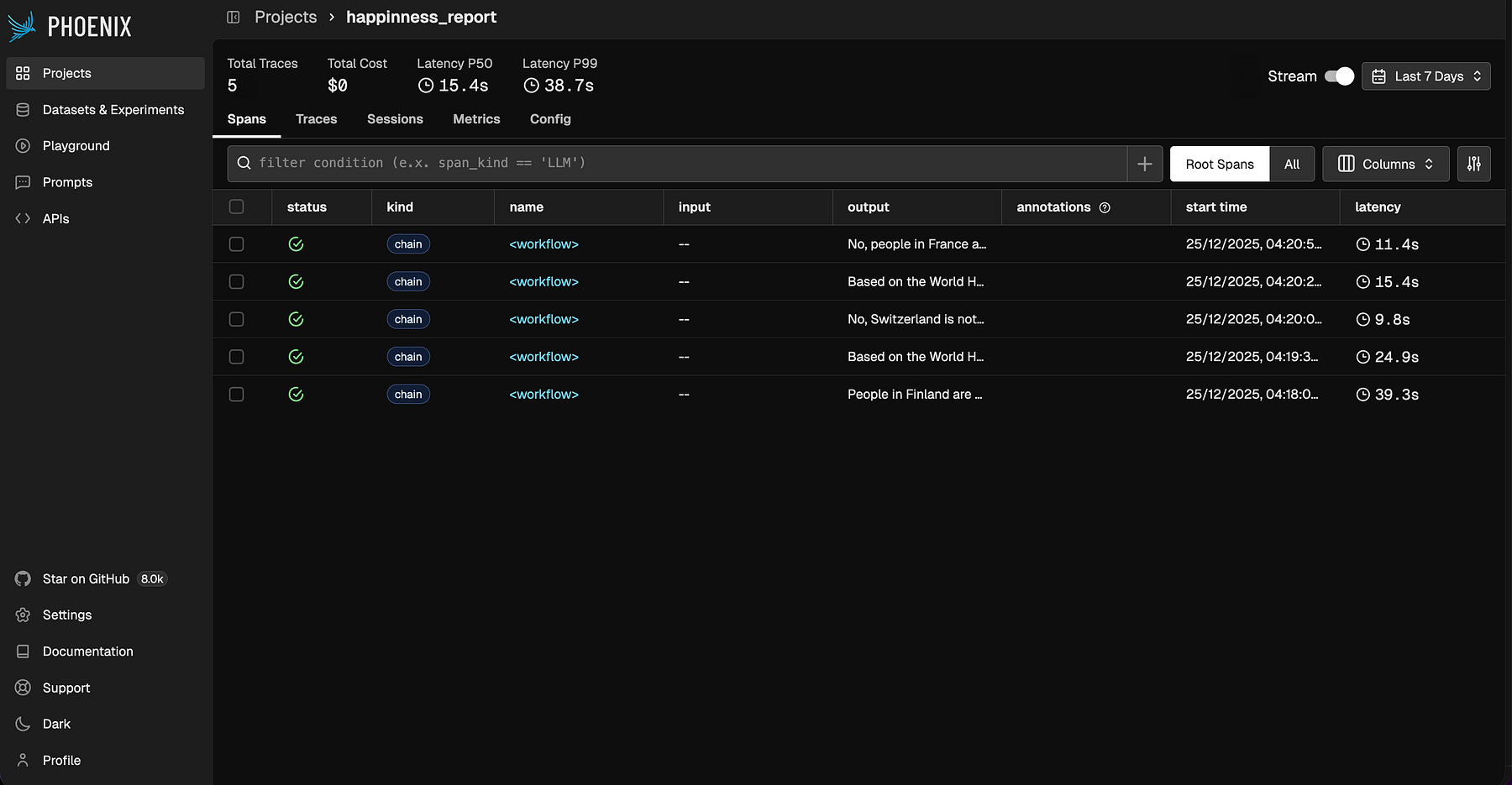
We are able to zoom in on one of many queries, like “Are folks total getting happier over time?”

This question takes fairly some time (about 25 seconds) as a result of it includes 5 instrument requires annually. If we count on a number of comparable questions on total developments, it would make sense to provide our agent a brand new instrument that may calculate abstract statistics suddenly.
That is precisely the place observability shines: by revealing bottlenecks and inefficiencies, it helps you cut back prices and ship a smoother expertise for customers.
Evaluations
Observability is about tracing how your utility works in manufacturing. This data is useful, however it isn’t sufficient to say whether or not the standard of solutions is sweet sufficient or whether or not a brand new model is performing higher. To reply such questions, we’d like evaluations. Thankfully, the NeMo Agent Toolkit can help us with evals as effectively.
First, let’s put collectively a small set of evaluations. We have to specify simply 3 fields: id, query and reply.
[
{
"id": "1",
"question": "In what country was the happiness score highest in 2021?",
"answer": "Finland"
},
{
"id": "2",
"question": "What contributed most to the happiness score in 2024?",
"answer": "Social Support"
},
{
"id": "3",
"question": "How UK's rank changed from 2019 to 2024?",
"answer": "The UK's rank dropped from 13th in 2019 to 23rd in 2024."
},
{
"id": "4",
"question": "Are people in France happier than in Germany based on the latest report?",
"answer": "No, Germany is at 22nd place in 2024 while France is at 33rd place."
},
{
"id": "5",
"question": "How much in percents are people in Poland happier in 2024 compared to 2019?",
"answer": "Happiness in Poland increased by 7.9% from 2019 to 2024. It was 6.1863 in 2019 and 6.6730 in 2024."
}
]Subsequent, we have to replace our YAML config to outline the place to retailer analysis outcomes and the place to search out the analysis dataset. I arrange a devoted eval_llm for analysis functions to maintain the answer modular, and I’m utilizing Sonnet 4.5 for it.
# Analysis configuration
eval:
basic:
output:
dir: ./tmp/nat/happiness_v3/eval/evals/
cleanup: false
dataset:
_type: json
file_path: src/happiness_v3/information/evals.json
evaluators:
answer_accuracy:
_type: ragas
metric: AnswerAccuracy
llm_name: eval_llm
groundedness:
_type: ragas
metric: ResponseGroundedness
llm_name: eval_llm
trajectory_accuracy:
_type: trajectory
llm_name: eval_llmI’ve outlined a number of evaluators right here. We’ll deal with Reply Accuracy and Response Groundedness from Ragas (an open-source framework for evaluating LLM workflows end-to-end), in addition to trajectory analysis. Let’s break them down.
Answer Accuracy measures how effectively a mannequin’s response aligns with a reference floor fact. It makes use of two “LLM-as-a-Choose” prompts, every returning a ranking of 0, 2, or 4. These scores are then transformed to a [0,1] scale and averaged. Greater scores point out that the mannequin’s reply carefully matches the reference.
- 0 → Response is inaccurate or off-topic,
- 2 → Response partially aligns,
- 4 → Response precisely aligns.
Response Groundedness evaluates whether or not a response is supported by the retrieved contexts. That’s, whether or not every declare could be discovered (totally or partially) within the supplied information. This works equally to Reply Accuracy, utilizing two distinct “LLM-as-a-Choose” prompts with scores of 0, 1, or 2, that are then normalised to a [0,1] scale.
- 0 → Not grounded in any respect,
- 1 → Partially grounded,
- 2 → Absolutely grounded.
Trajectory Analysis tracks the intermediate steps and power calls executed by the LLM, serving to to observe the reasoning course of. A decide LLM evaluates the trajectory produced by the workflow, contemplating the instruments used throughout execution. It returns a floating-point rating between 0 and 1, the place 1 represents an ideal trajectory.
Let’s run evaluations to see the way it works in apply.
nat eval --config_file src/happiness_v3/configs/config.ymlBecause of operating the evaluations, we get a number of recordsdata within the output listing we specified earlier. One of the crucial helpful ones is workflow_output.json. This file accommodates execution outcomes for every pattern in our analysis set, together with the unique query, the reply generated by the LLM, the anticipated reply, and an in depth breakdown of all intermediate steps. This file can assist you hint how the system labored in every case.
Right here’s a shortened instance for the primary pattern.
{
"id": 1,
"query": "In what nation was the happiness rating highest in 2021?",
"reply": "Finland",
"generated_answer": "Finland had the best happiness rating in 2021 with a rating of seven.821.",
"intermediate_steps": [...],
"expected_intermediate_steps": []
}For Reply Accuracy and Response Groundedness, we achieved the best attainable scores (1.0 out of 1.0 on common), which is all the time good to see. Right here is the returned file.
{
"average_score": 1.0,
"eval_output_items": [
{
"id": 1,
"score": 1.0,
"reasoning": {
"user_input": "In what country was the happiness score highest in 2021?",
"reference": "Finland",
"response": "Finland had the highest happiness score in 2021 with a score of 7.821.",
"retrieved_contexts": [...]
}
},
{
"id": 2,
"rating": 1.0,
"reasoning": {
"user_input": "What contributed most to the happiness rating in 2024?",
"reference": "Social Assist",
"response": "In 2024, **Social Assist** contributed most to the happiness rating, with a mean affect of 1.333 factors. This was adopted very carefully by **GDP per capita** with an affect of 1.319 factors. These two components had been considerably extra influential than different contributors like life expectancy (0.551), freedom (0.749), generosity (0.113), and perceptions of corruption (0.147). This means that having sturdy social connections and relationships, together with financial prosperity, had been the first drivers of happiness throughout international locations in 2024.",
"retrieved_contexts": [...]
}
},
{
"id": 3,
"rating": 1.0,
"reasoning": {
"user_input": "How UK's rank modified from 2019 to 2024?",
"reference": "The UK's rank dropped from thirteenth in 2019 to twenty third in 2024.",
"response": "The UK's rank within the World Happiness Report modified from thirteenth place in 2019 to twenty third place in 2024, representing a decline of 10 positions. The happiness rating additionally decreased from 7.1645 in 2019 to six.7280 in 2024.",
"retrieved_contexts": [...]
}
},
{
"id": 4,
"rating": 1.0,
"reasoning": {
"user_input": "Are folks in France happier than in Germany primarily based on the most recent report?",
"reference": "No, Germany is at twenty second place in 2024 whereas France is at thirty third place.",
"response": "Based mostly on the most recent 2024 World Happiness Report, folks in Germany are happier than folks in France. Germany has a happiness rating of 6.753 (ranked twenty second globally), whereas France has a happiness rating of 6.593 (ranked thirty third globally). The distinction is 0.16 factors in Germany's favor.",
"retrieved_contexts": [...]
}
},
{
"id": 5,
"rating": 1.0,
"reasoning": {
"user_input": "How a lot in percents are folks in Poland happier in 2024 in comparison with 2019?",
"reference": "Happiness in Poland elevated by 7.9% from 2019 to 2024. It was 6.1863 in 2019 and 6.6730 in 2024.",
"response": "Folks in Poland are roughly 7.87% happier in 2024 in comparison with 2019. The happiness rating elevated from 6.1863 in 2019 to six.6730 in 2024, representing a rise of 0.4867 factors or about 7.87%.",
"retrieved_contexts": [...]
}
}
]
}For trajectory analysis, we achieved a mean rating of 0.95. To know the place the mannequin fell brief, let’s have a look at one non-ideal instance. For the fifth query, the decide accurately recognized that the agent adopted a suboptimal path: it took 8 steps to achieve the ultimate reply, despite the fact that the identical consequence might have been achieved in 4–5 steps. Because of this, this trajectory obtained a rating of 0.75 out of 1.0.
Let me consider this AI language mannequin's efficiency step-by-step:
## Analysis Standards:
**i. Is the ultimate reply useful?**
Sure, the ultimate reply is evident, correct, and straight addresses the query.
It offers each the share improve (7.87%) and explains the underlying
information (happiness scores from 6.1863 to six.6730). The reply is well-formatted
and simple to know.
**ii. Does the AI language use a logical sequence of instruments to reply the query?**
Sure, the sequence is logical:
1. Question nation statistics for Poland
2. Retrieve the info displaying happiness scores for a number of years together with
2019 and 2024
3. Use a calculator to compute the share improve
4. Formulate the ultimate reply
This can be a smart strategy to the issue.
**iii. Does the AI language mannequin use the instruments in a useful means?**
Sure, the instruments are used appropriately:
- The `country_stats` instrument efficiently retrieved the related happiness information
- The `calculator_agent` accurately computed the share improve utilizing
the right components
- The Python analysis instrument carried out the precise calculation precisely
**iv. Does the AI language mannequin use too many steps to reply the query?**
That is the place there's some inefficiency. The mannequin makes use of 8 steps whole, which
consists of some redundancy:
- Steps 4-7 seem to contain a number of calls to calculate the identical proportion
(the calculator_agent is invoked, which then calls Claude Opus, which calls
evaluate_python, and returns by the chain)
- Step 7 appears to repeat what was already accomplished in steps 4-6
Whereas the reply is appropriate, there's pointless duplication. The calculation
might have been accomplished extra effectively in 4-5 steps as a substitute of 8.
**v. Are the suitable instruments used to reply the query?**
Sure, the instruments chosen are acceptable:
- `country_stats` was the proper instrument to get happiness information for Poland
- `calculator_agent` was acceptable for computing the share change
- The underlying `evaluate_python` instrument accurately carried out the mathematical
calculation
## Abstract:
The mannequin efficiently answered the query with correct information and proper
calculations. The logical move was sound, and acceptable instruments had been chosen.
Nevertheless, there was some inefficiency within the execution with redundant steps
within the calculation part.Trying on the reasoning, this seems to be a surprisingly complete analysis of your complete LLM workflow. What’s particularly precious is that it really works out of the field and doesn’t require any ground-truth information. I might undoubtedly advise utilizing this analysis to your functions.
Evaluating totally different variations
Evaluations develop into particularly highly effective when you could examine totally different variations of your utility. Think about a group centered on value optimisation and contemplating a swap from the costlier sonnet mannequin to haiku. With NAT, altering the mannequin takes lower than a minute, however doing so with out validating high quality could be dangerous. That is precisely the place evaluations shine.
For this comparability, we’ll additionally introduce one other observability instrument: W&B Weave. It offers significantly useful visualisations and side-by-side comparisons throughout totally different variations of your workflow.
To get began, you’ll want to enroll on the W&B website and acquire an API key. W&B is free to make use of for private initiatives.
export WANDB_API_KEY=Subsequent, set up the required packages and plugins.
uv pip set up wandb weave
uv pip set up "nvidia-nat[weave]"We additionally must replace our YAML config. This consists of including Weave to the telemetry part and introducing a workflow alias so we are able to clearly distinguish between totally different variations of the applying.
basic:
telemetry:
tracing:
phoenix:
_type: phoenix
endpoint: http://localhost:6006/v1/traces
challenge: happiness_report
weave: # specified Weave
_type: weave
challenge: "nat-simple"
eval:
basic:
workflow_alias: "nat-simple-sonnet-4-5" # added alias
output:
dir: ./.tmp/nat/happiness_v3/eval/evals/
cleanup: false
dataset:
_type: json
file_path: src/happiness_v3/information/evals.json
evaluators:
answer_accuracy:
_type: ragas
metric: AnswerAccuracy
llm_name: chat_llm
groundedness:
_type: ragas
metric: ResponseGroundedness
llm_name: chat_llm
trajectory_accuracy:
_type: trajectory
llm_name: chat_llmFor the haiku model, I created a separate config the place each chat_llm and calculator_llm use haiku as a substitute of sonnet.
Now we are able to run evaluations for each variations.
nat eval --config_file src/happiness_v3/configs/config.yml
nat eval --config_file src/happiness_v3/configs/config_simple.ymlAs soon as the evaluations are full, we are able to head over to the W&B interface and discover a complete comparability report. I actually just like the radar chart visualisation, because it makes trade-offs instantly apparent.
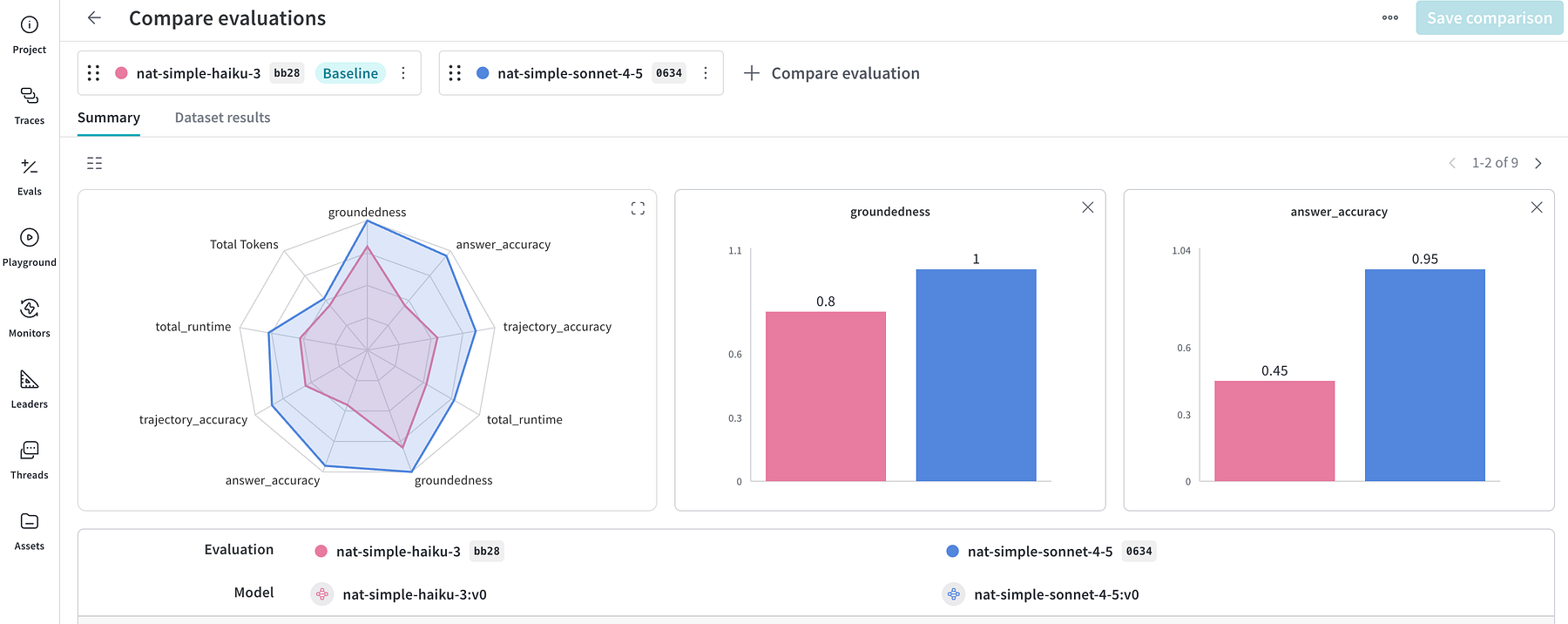

With sonnet, we observe larger token utilization (and better value per token) in addition to slower response instances (24.8 seconds in comparison with 16.9 seconds for haiku). Nevertheless, regardless of the clear positive factors in pace and value, I wouldn’t advocate switching fashions. The drop in high quality is just too giant: trajectory accuracy falls from 0.85 to 0.55, and reply accuracy drops from 0.95 to 0.45. On this case, evaluations helped us keep away from breaking the person expertise within the pursuit of value optimisation.
You’ll find the complete implementation on GitHub.
Abstract
On this article, we explored the NeMo Agent Toolkit’s observability and analysis capabilities.
- We labored with two observability instruments (Phoenix and W&B Weave), each of which combine seamlessly with NAT and permit us to log what’s occurring inside our system in manufacturing, in addition to seize analysis outcomes.
- We additionally walked by how one can configure evaluations in NAT and used W&B Weave to check the efficiency of two totally different variations of the identical utility. This made it simple to motive about trade-offs between value, latency, and reply high quality.
The NeMo Agent Toolkit delivers strong, production-ready options for observability and evaluations — foundational items of any critical LLM utility. Nevertheless, the standout for me was W&B Weave, whose analysis visualisations make evaluating fashions and trade-offs remarkably simple.
Thanks for studying. I hope this text was insightful. Keep in mind Einstein’s recommendation: “The essential factor is to not cease questioning. Curiosity has its personal motive for current.” Could your curiosity lead you to your subsequent nice perception.
Reference
This text is impressed by the “Nvidia’s NeMo Agent Toolkit: Making Agents Reliable” brief course from DeepLearning.AI.