


With the speedy developments in Massive Language Fashions (LLMs) and Imaginative and prescient-Language Fashions (VLMs), many imagine OCR has turn into out of date. If LLMs can “see” and “learn” paperwork, why not use them straight for textual content extraction?
The reply lies in reliability. Are you able to at all times be a 100% certain of the veracity of textual content output that LLMs interpret from a doc/picture? We put this to check with a easy experiment. We requested colleagues to make use of any LLM of their option to extract a listing of passenger names (10) from a pattern PDF flight ticket.
💡
Solely NotebookLM and Deepseek obtained the listing of names utterly proper!
Whereas LLMs can interpret and summarize paperwork, they lack the precision and structured output required for vital enterprise purposes the place 100% information accuracy is essential. Moreover, LLMs require important computational sources, making them expensive and impractical for large-scale doc processing, particularly in enterprise and edge deployments.
OCR, alternatively, is optimized for effectivity, operating on low-power units whereas delivering constant outcomes. When accuracy is non-negotiable whether or not in monetary data, authorized contracts, or regulatory compliance, OCR stays essentially the most reliable resolution.
Not like LLMs, OCR APIs present confidence scores and bounding bins, permitting builders to detect uncertainties in extracted textual content. This stage of management is essential for companies that can’t afford incorrect or hallucinated information. That’s why OCR APIs proceed to be broadly utilized in doc automation workflows, AI-driven information extraction, and enterprise purposes.
To evaluate the state of OCR in 2025, we benchmarked 9 of the preferred OCR APIs, protecting business options, open-source OCR engines, and doc processing frameworks. Our objective is to supply an goal, data-driven comparability that helps builders and enterprises select the most effective software for his or her wants.
Methodology
Dataset Choice:
To make sure a complete analysis of OCR APIs or OCR fashions in real-world situations, we chosen datasets that embody a various vary of doc sorts and challenges generally encountered in sensible purposes. Our dataset decisions embrace:
- Widespread Enterprise Paperwork: Types, invoices, and monetary statements containing structured textual content.
- Receipts: Printed transaction slips with various fonts, noise, and pale textual content.
- Low-Decision Photos: Paperwork captured beneath suboptimal situations, mimicking real-world scanning and images limitations.
- Handwritten Textual content: Samples with completely different handwriting kinds to check handwriting recognition capabilities.
- Blurred or Distorted Textual content: Photos with movement blur or compression artifacts to evaluate OCR robustness.
- Rotated or Skewed Textual content: Paperwork scanned or photographed at an angle, requiring superior textual content alignment dealing with.
- Tabular Knowledge: Paperwork containing structured tabular data, difficult for OCR fashions to protect format integrity.
- Dense Textual content: Textual content-heavy paperwork, equivalent to account opening varieties, to judge efficiency in high-content areas.
To make sure our benchmark covers all these real-world challenges, we choose the next datasets:
- STROIE (link to dataset)
- FUNSD (link to dataset)
These datasets present a complete testbed for evaluating OCR efficiency throughout sensible and actual life situations.
Fashions Choice
To judge OCR efficiency throughout completely different situations, we embrace a mixture of business APIs, open-source OCR fashions, and doc processing frameworks. This ensures a balanced comparability between proprietary options and freely obtainable alternate options. The fashions utilized in our benchmark are:
- Fashionable Industrial OCR APIs:
- Google Cloud Imaginative and prescient AI
- Azure AI Doc Intelligence
- Amazon Textract
- Fashionable Open-Supply OCR APIs:
- Surya
- PaddleOCR
- RapidOCR
- Extractous
- Fashionable Open-Supply Doc Processing Frameworks:
To exhibit how every OCR API processes a picture, we offer code snippets for operating OCR utilizing each business APIs and open-source frameworks. These examples present how you can load a picture, apply OCR, and extract the textual content, providing a sensible information for implementation and comparability. Under are the code snippets for every mannequin:
- Google Cloud Imaginative and prescient AI: First step is to arrange a brand new Google Cloud Venture. Within the Google Cloud Console, navigate to APIs & Providers → Library, seek for Imaginative and prescient API, and click on Allow. Go to APIs & Providers → Credentials, click on Create Credentials → Service Account, title it (e.g., vision-ocr-service), and click on Create & Proceed. Assign the Proprietor (or Editor) function and click on Achieved. Now, in Service Accounts, choose the account, go to Keys → Add Key → Create New Key, select JSON, and obtain the .json file.
Required Packages:
pip set up google-cloud-vision
from google.cloud import imaginative and prescient
from google.oauth2 import service_account
credentials = service_account.Credentials.from_service_account_file("/content material/ocr-nanonets-cea4ddeb1dd2.json") #path to the json file downloaded
shopper = imaginative and prescient.ImageAnnotatorClient(credentials=credentials)
def detect_text(image_path):
"""Detects textual content in a picture utilizing Google Cloud Imaginative and prescient AI."""
with open(image_path, 'rb') as image_file:
content material = image_file.learn()
picture = imaginative and prescient.Picture(content material=content material)
response = shopper.text_detection(picture=picture)
texts = response.text_annotations
if texts:
return texts[0].description
else:
return "No textual content detected."
if response.error.message:
elevate Exception(f"Error: {response.error.message}")
# Substitute together with your picture path
image_path = "/content material/drive/MyDrive/OCR_datasets/STROIE/test_data/img/X00016469670.jpg"
print(detect_text(image_path))
- Azure AI Doc Intelligence: Create an Azure Account (Azure Portal) to get $200 free credit for 30 days. Within the Azure Portal, go to Create a Useful resource, seek for Azure AI Doc Intelligence (Kind Recognizer), and click on Create. Select a Subscription, Useful resource Group, Area (nearest to you), set Pricing Tier to Free (if obtainable) or Customary, then click on Overview + Create → Create. As soon as created, go to the Azure AI Doc Intelligence useful resource, navigate to Keys and Endpoint, and replica the API Key and Endpoint.
Required Packages:
pip set up azure-ai-documentintelligence
from azure.ai.documentintelligence import DocumentIntelligenceClient
from azure.core.credentials import AzureKeyCredential
import io
# Substitute together with your Azure endpoint and API key
AZURE_ENDPOINT = "https://your-region.api.cognitive.microsoft.com/"
AZURE_KEY = "your-api-key"
shopper = DocumentIntelligenceClient(AZURE_ENDPOINT, AzureKeyCredential(AZURE_KEY))
def extract_text(image_path):
"""Extracts textual content from a picture utilizing Azure AI Doc Intelligence."""
with open(image_path, "rb") as image_file:
image_data = image_file.learn()
poller = shopper.begin_analyze_document("prebuilt-read", doc=image_data)
outcome = poller.outcome()
extracted_text = []
for web page in outcome.pages:
for line in web page.traces:
extracted_text.append(line.content material)
print("Detected textual content:")
print("n".be a part of(extracted_text))
image_path = image_path
extract_text(image_path)
- Amazon Textract: Create an AWS Account (AWS Sign-Up) to entry Amazon Textract’s free-tier (1,000 pages/month for 3 months). Within the AWS Administration Console, go to IAM (Identification & Entry Administration) → Customers → Create Person, title it (e.g., textract-user), and choose Programmatic Entry. Below Permissions, connect AmazonTextractFullAccess and AmazonS3ReadOnlyAccess (if utilizing S3). Click on Create Person and replica the Entry Key ID and Secret Entry Key.
Required Packages:
pip set up boto3
Set Setting Variables:
export AWS_ACCESS_KEY_ID="your-access-key"
export AWS_SECRET_ACCESS_KEY="your-secret-key"
export AWS_REGION="your-region"
import boto3
textract = boto3.shopper("textract", region_name="us-east-1")
def extract_text(image_path):
"""Extracts textual content from a picture utilizing Amazon Textract."""
with open(image_path, "rb") as image_file:
image_bytes = image_file.learn()
response = textract.detect_document_text(Doc={"Bytes": image_bytes})
extracted_text = []
for merchandise in response["Blocks"]:
if merchandise["BlockType"] == "LINE":
extracted_text.append(merchandise["Text"])
print("Detected textual content:")
print("n".be a part of(extracted_text))
image_path = image_path
extract_text(image_path)
- Surya : Use pip set up surya-ocr to obtain the mandatory packages. Then create a python file with the next code and run it in terminal.
from PIL import Picture
from surya.recognition import RecognitionPredictor
from surya.detection import DetectionPredictor
picture = Picture.open(image_path)
langs = ["en"]
recognition_predictor = RecognitionPredictor()
detection_predictor = DetectionPredictor()
predictions = recognition_predictor([image], [langs], detection_predictor)
- PaddleOCR : Use “pip set up paddleocr paddlepaddle” to put in the required packages. Then create a python file with the next code and run it in terminal.
from paddleocr import PaddleOCR
ocr = PaddleOCR(use_angle_cls=True, lang="en")
outcome = ocr.ocr(image_path, cls=True)
- RapidOCR : Use “pip set up rapidocr_onnxruntime” to put in the required packages. Then create a python file with the next code and run it in terminal.
from rapidocr_onnxruntime import RapidOCR
engine = RapidOCR()
img_path = image_path
outcome, elapse = engine(img_path)
- Extractous: Use “sudo apt set up tesseract-ocr tesseract-ocr-deu” to put in the required packages. Then create a python file with the next code and run it in terminal.
from extractous import Extractor, TesseractOcrConfig
extractor = Extractor().set_ocr_config(TesseractOcrConfig().set_language("en"))
outcome, metadata = extractor.extract_file_to_string(image_path)
print(outcome)
- Marker: Use “pip set up marker-pdf” to put in the required packages. Then in terminal use the next code.
!marker_single image_path --output_dir saving_directory --output_format json
- Unstructured-IO: Use “pip set up “unstructured[image]”” to put in the required packages. Then create a python file with the next code and run it in terminal.
from unstructured.partition.auto import partition
components = partition(filename=image_path)
print("nn".be a part of([str(el) for el in elements]))
Analysis Metrics
To evaluate the effectiveness of every OCR mannequin, we consider each accuracy and efficiency utilizing the next metrics:
- Character Error Fee (CER): Measures the ratio of incorrect characters (insertions, deletions, and substitutions) to the whole characters within the floor reality textual content. Decrease CER signifies higher accuracy.
- Phrase Error Fee (WER): Just like CER however operates on the phrase stage, calculating errors relative to the whole variety of phrases. It helps assess how properly fashions acknowledge full phrases.
- ROUGE Rating: A textual content similarity metric that compares OCR output with the bottom reality based mostly on overlapping n-grams, capturing each precision and recall.
For efficiency analysis, we measure:
- Inference Time (Latency per Picture): The time taken by every mannequin to course of a single picture, indicating pace and effectivity in real-world purposes.
Value Analysis:
- For business OCR APIs, price is set by their pricing fashions, sometimes based mostly on the variety of processed pages or pictures.
- For open-source OCR APIs, whereas there aren’t any direct utilization prices, we assess computational overhead by measuring reminiscence utilization throughout inference.
Benchmarking Outcomes
For the reason that datasets used—STROIE (completely different receipt pictures) and FUNSD (enterprise paperwork with tabular layouts)—comprise numerous format kinds, the extracted textual content varies throughout fashions based mostly on their skill to protect construction. This variation impacts the Phrase Error Fee (WER) and Character Error Fee (CER), as these metrics depend upon the place of phrases and characters within the output.
A excessive error price signifies {that a} mannequin struggles to keep up the chronological order of textual content, particularly in complicated layouts and tabular codecs.
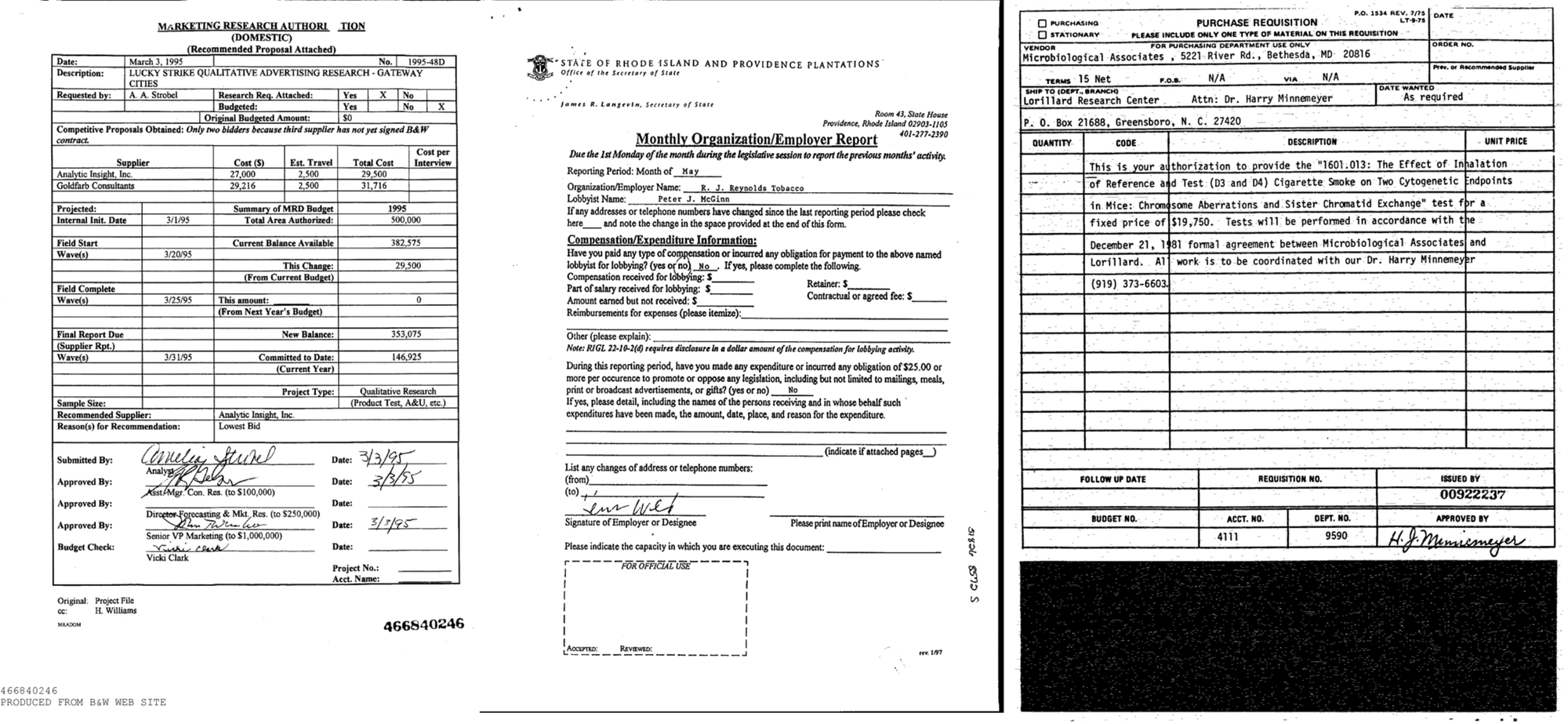
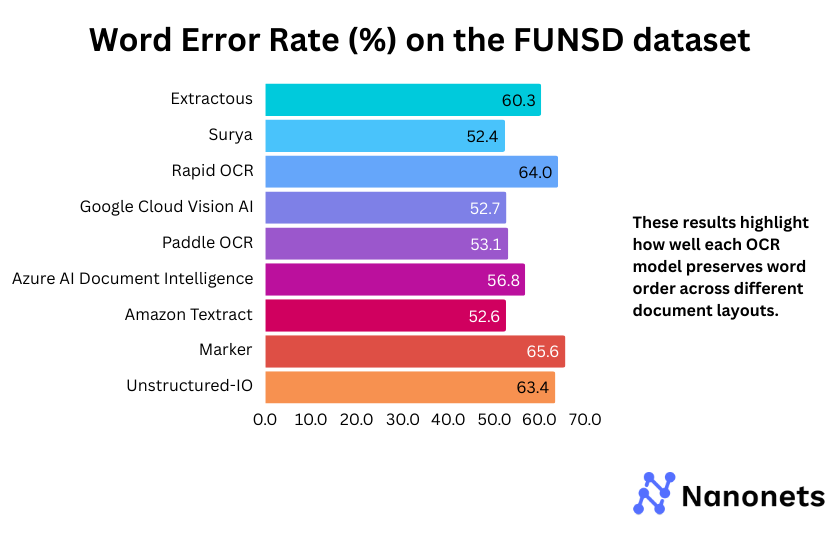
1. Phrase Error Fee
WER of every mannequin on the FUNSD and STROIE datasets is offered under. These outcomes spotlight how properly every mannequin preserves phrase order throughout completely different doc layouts.
2. Character Error Fee
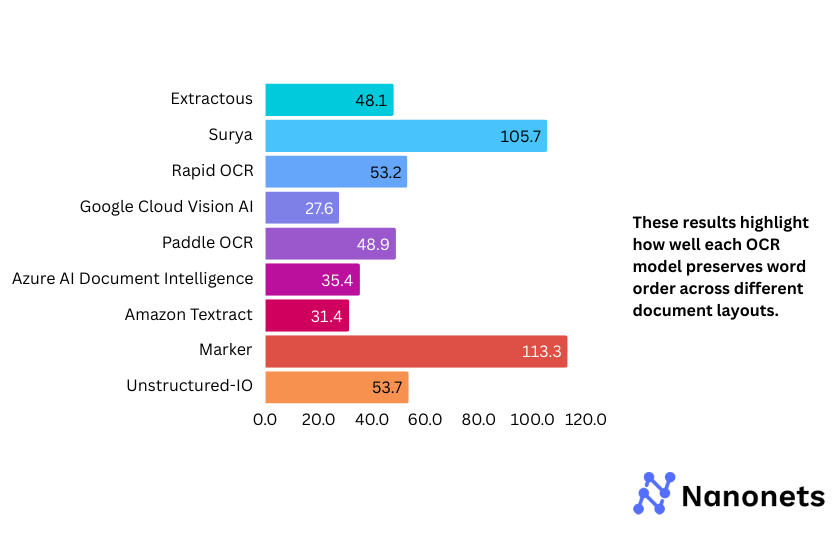
CER of every mannequin on the FUNSD and STROIE datasets is offered under. These outcomes point out how precisely every mannequin captures character-level textual content whereas dealing with completely different doc layouts.
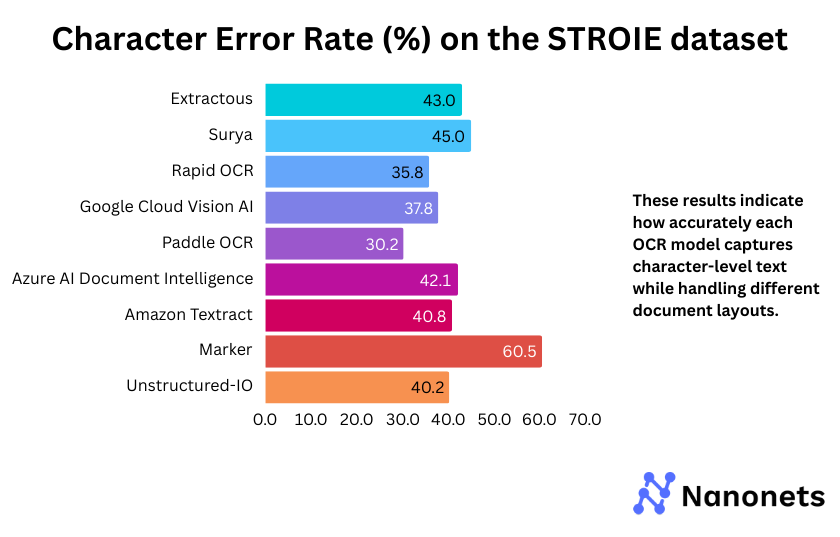
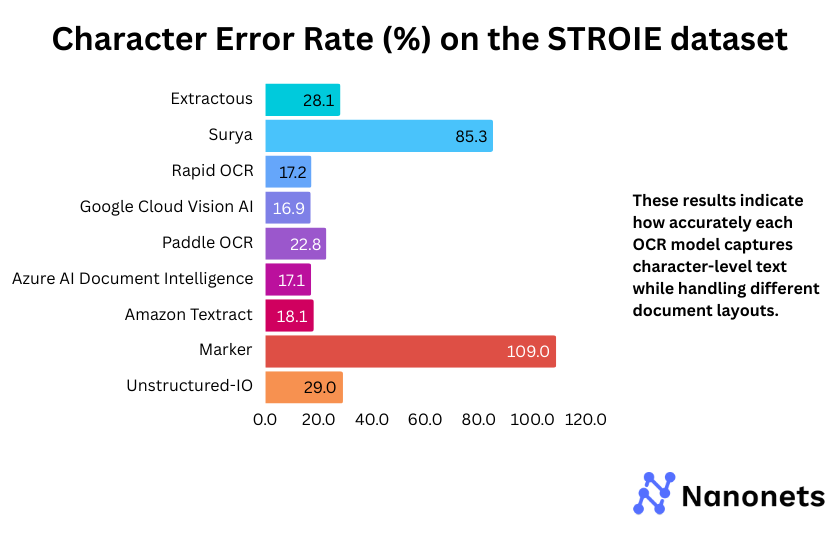
Why are the WER and CER metrics for Surya and Marker so excessive on the STROIE dataset?
STROIE’s intricate layouts make OCR tough. Surya tries to fill gaps by inserting further phrases, resulting in excessive WER and CER, even after post-processing. Marker, which makes use of Surya for OCR and outputs markdown textual content, inherits these points. The markdown formatting additional misaligns textual content, worsening the error charges.
Variation in Mannequin Efficiency Throughout Datasets
OCR fashions carry out otherwise based mostly on dataset construction. Google Cloud Imaginative and prescient AI and Azure AI Doc Intelligence deal with numerous layouts higher, whereas open-source fashions like RapidOCR and Surya battle with structured codecs, resulting in extra errors.
For the reason that fashions battle to protect layouts, resulting in excessive WER and CER, we use one other metric—ROUGE Rating—to evaluate textual content similarity between the mannequin’s output and the bottom reality. Not like WER and CER, ROUGE focuses on content material similarity slightly than phrase place. Which means that no matter format preservation, a excessive ROUGE rating signifies that the extracted textual content intently matches the reference, whereas a low rating suggests important content material discrepancies.
3. ROUGE Rating
ROUGE Rating of every mannequin on the FUNSD and STROIE datasets is offered under. These outcomes replicate the content material similarity between the extracted textual content and the bottom reality, no matter format preservation.
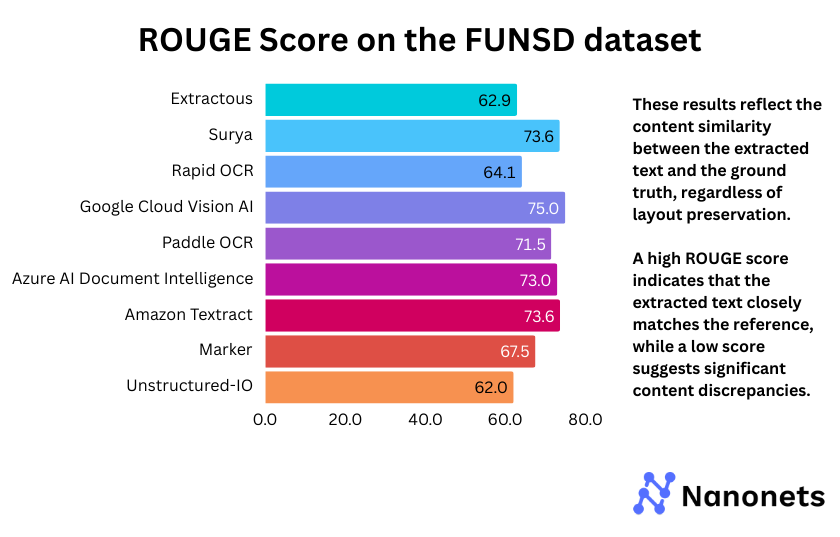
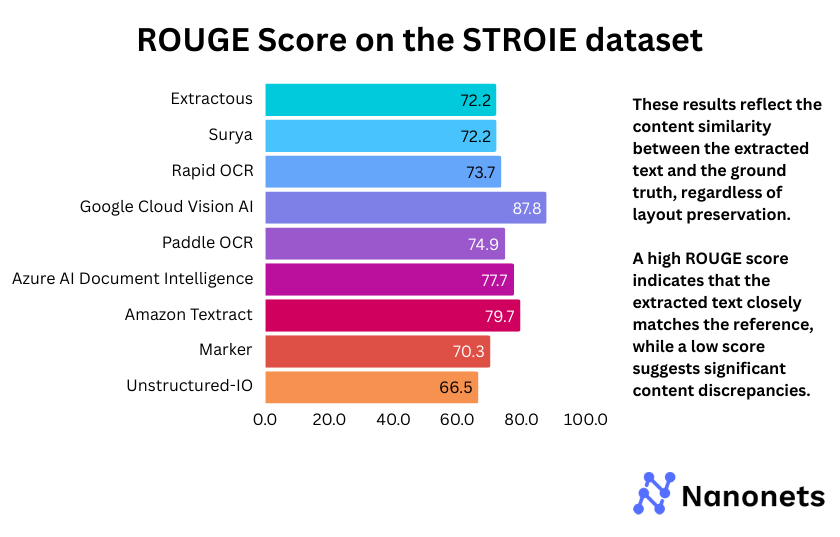
The ROUGE scores reveal that Google Cloud Imaginative and prescient AI persistently outperforms different fashions throughout each FUNSD (75.0%) and STROIE (87.8%), indicating superior textual content extraction. Surya and Marker, which depend on the identical backend, present comparable efficiency, although Marker barely lags on STROIE (70.3%). Extractous and Unstructured-IO rating the bottom in each datasets, suggesting weaker textual content coherence. PaddleOCR and Azure AI Doc Intelligence obtain balanced outcomes, making them aggressive alternate options. The general pattern highlights the power of business APIs, whereas open-source fashions exhibit blended efficiency.
💡
4. Latency per picture
Latency per picture for every mannequin is offered under. This measures the time taken by every mannequin to carry out OCR on one picture, offering insights into their effectivity and processing pace.
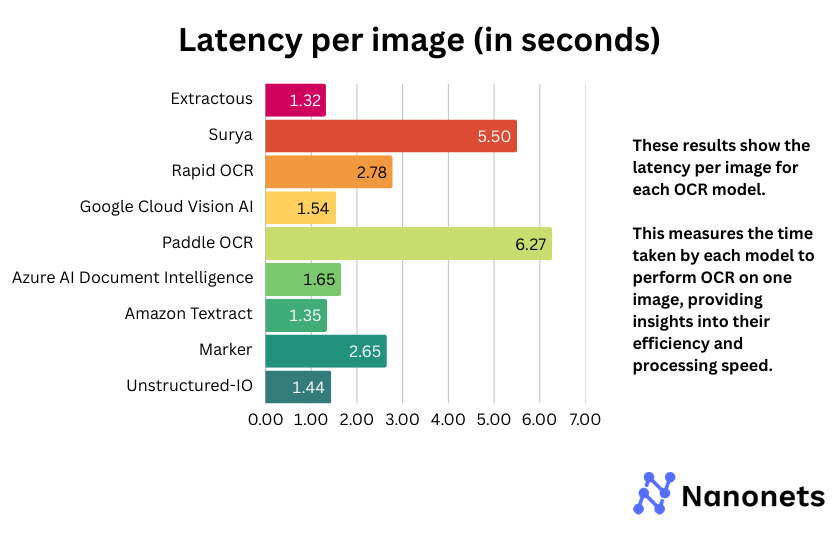
The latency evaluation reveals that Google Cloud Imaginative and prescient AI, Amazon Textract, and Extractous keep steadiness between pace and accuracy. Surya and Paddle OCR exhibit notably larger inference occasions, suggesting potential inefficiencies. Open-source fashions like Speedy OCR and Marker fluctuate in efficiency, with some providing aggressive speeds whereas others lag behind. Azure AI Doc Intelligence additionally reveals reasonable latency, making it a viable alternative relying on the use case.
5. Value or reminiscence utilization per picture
For business APIs, we current the utilization price (price per 1000 pictures processed). For open-source fashions, the metric signifies reminiscence consumption as a proxy for price, offering insights into their useful resource effectivity.
| OCR API | Value per 1,000 Pages |
|---|---|
| Google Cloud Imaginative and prescient AI | $1.50 |
| Amazon Textract | $1.50 |
| Azure AI Doc Intelligence | $0.50 |
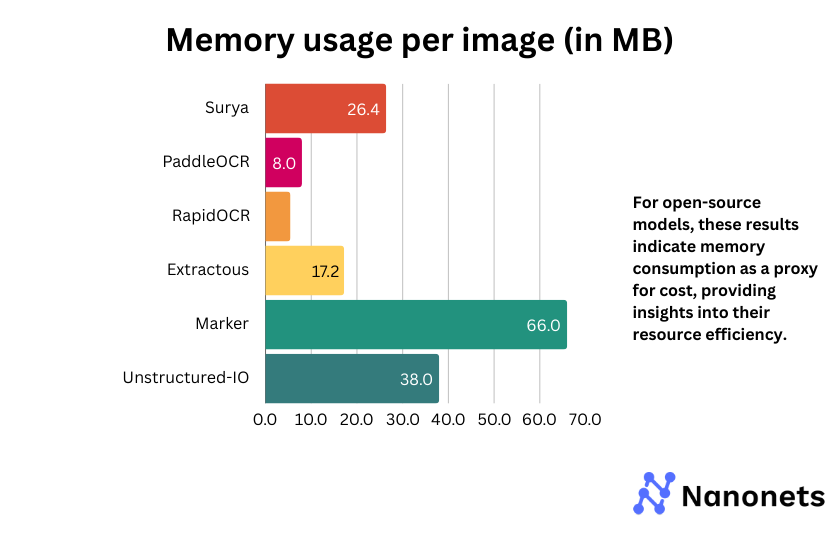
Amongst open-source fashions, Marker and Unstructured-IO have considerably larger reminiscence consumption, which can affect deployment in resource-constrained environments. Surya and Extractous strike a steadiness between efficiency and reminiscence effectivity. PaddleOCR and RapidOCR are essentially the most light-weight choices, making them very best for low-memory situations.
Conclusion
Primarily based on the analysis throughout latency, inference time, and ROUGE rating, no single mannequin dominates in all features. Nevertheless, some fashions stand out in particular areas:
- Greatest Latency & Inference Time: Extractous and Amazon Textract exhibit the quickest response occasions, making them very best for real-time purposes.
- Greatest ROUGE Rating (Accuracy): Google Cloud Imaginative and prescient AI and Azure AI Doc Intelligence obtain the best accuracy in textual content recognition, making them robust candidates for purposes requiring exact OCR.
- Greatest Reminiscence Effectivity: RapidOCR and PaddleOCR eat the least reminiscence, making them extremely appropriate for low-resource environments.
Greatest Mannequin General
Contemplating a steadiness between accuracy, pace, and effectivity, Google Cloud Imaginative and prescient AI emerges as the most effective general performer. It gives robust accuracy with aggressive inference time. Nevertheless, for open sourced fashions, PaddleOCR and RapidOCR provide the most effective trade-off between accuracy, pace and reminiscence effectivity.
Leaderboard of Greatest OCR APIs based mostly on completely different efficiency metrics:
| Metric | Greatest Mannequin | Rating / Worth |
|---|---|---|
| Highest Accuracy (ROUGE Rating) | Google Cloud Imaginative and prescient AI | Greatest ROUGE Rating |
| Greatest Format Dealing with (Least WER & CER) | Google Cloud Imaginative and prescient AI | Lowest WER & CER |
| Quickest OCR (Lowest Latency) | Extractous | Lowest Processing Time |
| Reminiscence Environment friendly | RapidOCR | Least Reminiscence Utilization |
| Most Value-Efficient amongst Industrial APIs | Azure AI Doc Intelligence | Lowest Value Per Web page |
LLM vs. Devoted OCR: A Case Examine
To grasp how OCR fashions evaluate to Massive Language Fashions (LLMs) in textual content extraction, we examined a difficult picture utilizing each LLaMa 3.2 11B Vision and RapidOCR, a small however devoted OCR mannequin.

Outcomes:
- LLaMa 3.2 11B Imaginative and prescient
- Struggled with faint textual content, failing to reconstruct sure phrases.
- Misinterpreted some characters and added hallucinated phrases.
- Took considerably longer to course of the picture.
- Used quite a lot of compute sources.
- RapidOCR
- Precisely extracted a lot of the textual content regardless of the tough situations.
- Ran effectively on very low compute sources.
Is OCR Nonetheless Related As we speak?
With the rise of multimodal LLMs able to decoding pictures and textual content, some imagine OCR could turn into out of date. Nevertheless, the fact is extra nuanced.
If you happen to or your finish clients must be 100% certain of knowledge you are extracting from paperwork or pictures, OCR nonetheless is your finest wager for now! Confidence scores and bounding bins from OCR APIs can be utilized to deduce when the output isn’t dependable.
With LLMs you may by no means be 100% certain of the veracity of the textual content output due to hallucinations and the insecurity scores.
Who Nonetheless Wants OCR?
- Enterprises Dealing with Excessive-Quantity Paperwork: Banks, authorized companies, and insurance coverage corporations depend on OCR for automated doc processing at scale.
- Governments and Compliance: Passport scanning, tax data, and regulatory filings nonetheless require OCR for structured extraction.
- AI-Powered Knowledge Pipelines: Many companies combine OCR with NLP pipelines to transform paperwork into structured information earlier than making use of AI fashions.
- Multilingual and Low-Useful resource Language Purposes: OCR stays important for digitizing uncommon scripts the place LLMs lack coaching information.
Why Ought to Enterprises Nonetheless Care About OCR When Everybody Desires LLMs?
- Accuracy and Reliability: LLMs generate hallucinations, whereas OCR ensures exact textual content extraction, making it vital for authorized, monetary, and authorities purposes.
- Velocity and Value Effectivity: OCR is light-weight and works on edge units, whereas LLMs require excessive compute sources and cloud inference prices.
- The longer term isn’t OCR vs. LLMs—it’s OCR and LLMs: OCR can extract clear textual content, and LLMs can then course of and interpret it for insights. AI-powered OCR fashions will proceed to enhance, integrating LLM reasoning for higher post-processing.
Closing Ideas
Whereas LLMs have expanded the chances of textual content extraction from pictures, OCR stays indispensable for structured, high-accuracy textual content retrieval and can at all times be essential for dependable doc processing. Somewhat than changing OCR, LLMs will complement it, bringing higher understanding, context, and automation to extracted information.