


To higher perceive MLA and in addition make this text self-contained, we’ll revisit a number of associated ideas on this part earlier than diving into the main points of MLA.
MHA in Decoder-only Transformers
Word that MLA is developed to speedup inference velocity in autoregressive textual content technology, so the MHA we’re speaking about beneath this context is for decoder-only Transformer.
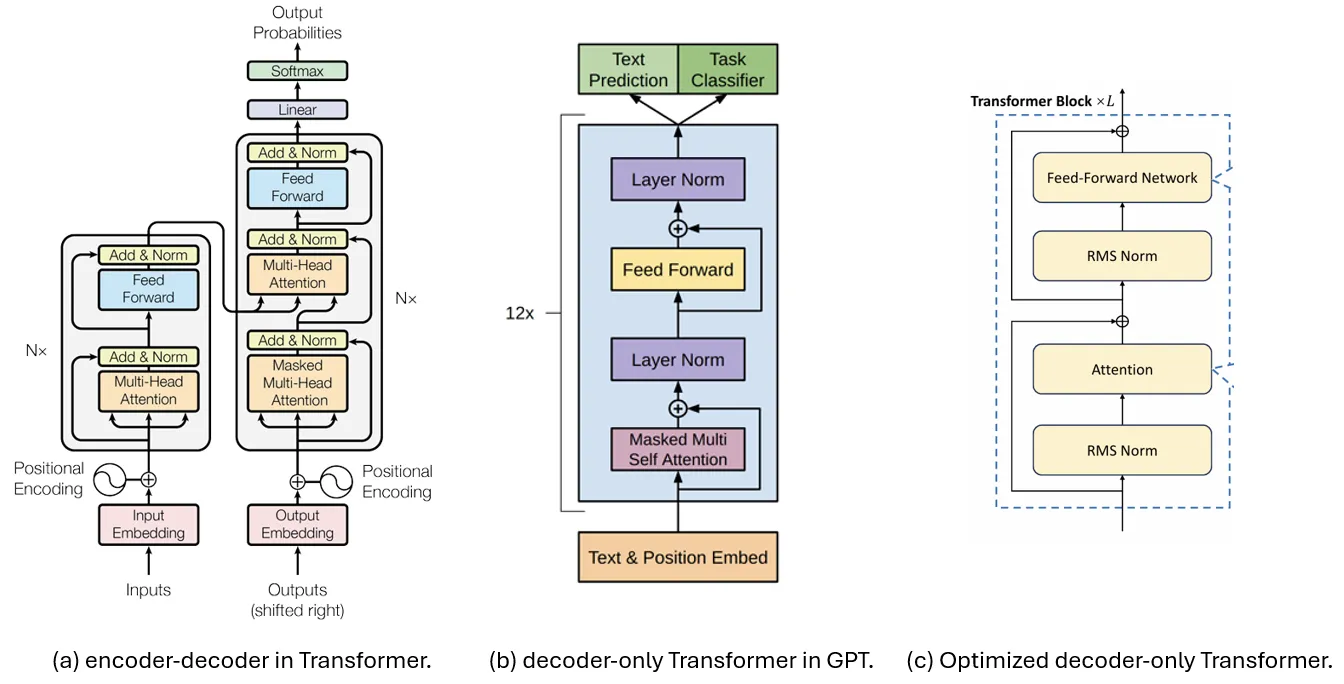
The determine beneath compares three Transformer architectures used for decoding, the place (a) exhibits each the encoder and decoder proposed within the unique “Consideration is All You Want” paper. Its decoder half is then simplified by [6], resulting in a decoder-only Transformer mannequin proven in (b), which is later utilized in many technology fashions like GPT [8].
These days, LLMs are extra generally to decide on the construction proven in (c) for extra steady coaching, with normalization utilized on the enter reasonably then output, and LayerNorm upgraded to RMS Norm. This can function the baseline structure we’ll talk about on this article.
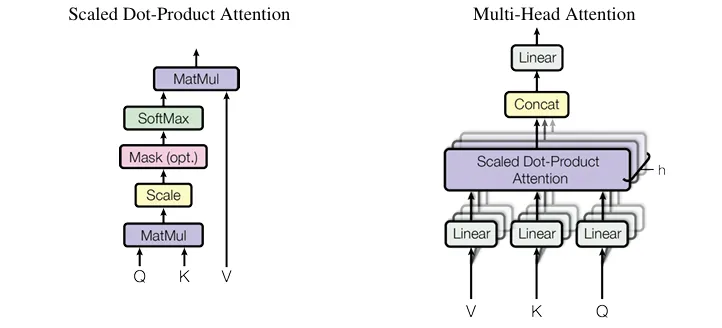
Inside this context, MHA calculation largely follows the method in [6], as proven within the determine beneath:
Assume we have now n_h consideration heads, and the dimension for every consideration head is represented as d_h, in order that the concatenated dimension shall be (h_n · d_h).
Given a mannequin with l layers, if we denote the enter for the t-th token in that layer as h_t with dimension d, we have to map the dimension of h_t from d to (h_n · d_h) utilizing the linear mapping matrices.
Extra formally, we have now (equations from [3]):

the place W^Q, W^Ok and W^V are the linear mapping matrices:
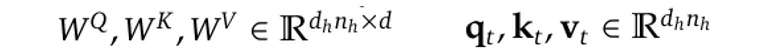
After such mapping, q_t, k_t and v_t shall be cut up into n_h heads to calculate the scaled dot-product consideration:
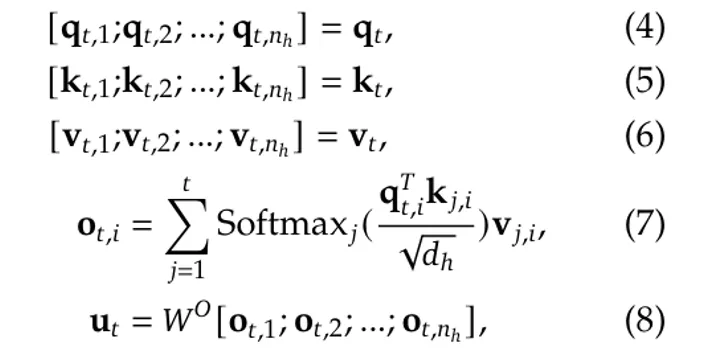
the place W^O is one other projection matrix to map the dimension inversely from (h_n · d_h) to d:

Word that the method described by Eqn.(1) to (8) above is only for a single token. Throughout inference, we have to repeat this course of for every newly generated token, which entails lots of repeated calculation. This results in a method referred to as Key-Worth cache.
Key-Worth Cache
As urged by its identify, Key-Worth cache is a method designed to speedup the autoregressive course of by caching and reusing the earlier keys and values, reasonably than re-computing them at every decoding step.
Word that KV cache is usually used solely in the course of the inference stage, since in coaching we nonetheless have to course of the whole enter sequence in parallel.
KV cache is often carried out as a rolling buffer. At every decoding step, solely the brand new question Q is computed, whereas the Ok and V saved within the cache shall be reused, in order that the eye shall be computed utilizing the brand new Q and reused Ok, V. In the meantime, the brand new token’s Ok and V will even be appended to the cache for later use.
Nonetheless, the speedup achieved by KV cache comes at a price of reminiscence, since KV cache usually scales with batch dimension × sequence size × hidden dimension × variety of heads, resulting in a reminiscence bottleneck when we have now bigger batch dimension or longer sequences.
That additional results in two strategies aiming at addressing this limitation: Multi-Question Consideration and Grouped-Question Consideration.
Multi-Question Consideration (MQA) vs Grouped-Question Consideration (GQA)
The determine beneath exhibits the comparability between the unique MHA, Grouped-Question Consideration (GQA) [10] and Multi-Question Consideration (MQA) [9].
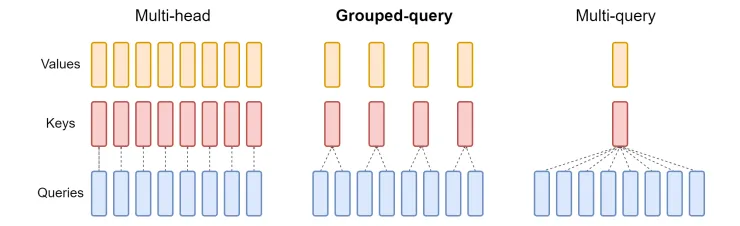
The fundamental thought of MQA is to share a single key and a single worth head throughout all question heads, which might considerably scale back reminiscence utilization however will even impression the accuracy of consideration.
GQA may be seen as an interpolating technique between MHA and MQA, the place a single pair of key and worth heads shall be shared solely by a bunch of question heads, not all queries. However nonetheless it will result in inferior outcomes in comparison with MHA.
Within the later sections, we’ll see how MLA manages to hunt a steadiness between reminiscence effectivity and modeling accuracy.
RoPE (Rotary Positional Embeddings)
One final piece of background we have to point out is RoPE [11], which encodes positional info straight into the eye mechanism by rotating the question and key vectors in multi-head consideration utilizing sinusoidal capabilities.
Extra particularly, RoPE applies a position-dependent rotation matrix to the question and key vectors at every token, and makes use of sine and cosine capabilities for its foundation however applies them in a singular technique to obtain rotation.
To see what makes it position-dependent, think about a toy embedding vector with solely 4 components, i.e., (x_1, x_2, x_3, x_4).
To use RoPE, we firstly group consecutive dimensions into pairs:
- (x_1, x_2) -> place 1
- (x_3, x_4) -> place 2
Then, we apply a rotation matrix to rotate every pair:
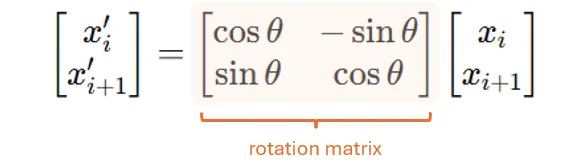
the place θ = θ(p) = p ⋅ θ_0, and θ_0 is a base frequency. In our 4-d toy instance, which means that (x_1, x_2) shall be rotated by θ_0, and (x_3, x_4) shall be rotated by 2 ⋅ θ_0.
Because of this we name this rotation matrix as position-dependent: at every place (or every pair), we’ll apply a distinct rotation matrix the place the rotation angle is set by place.
RoPE is extensively utilized in fashionable LLMs as a result of its effectivity in encoding lengthy sequences, however as we will see from the above method, it’s position-sensitive to each Q and Ok, making it incompatible with MLA in some methods.